머신러닝이란
인공지능의 한 분야로, 인간의 학습 능력을 기계를 통해 구현하는 방법이다. 주어진 데이터로부터 스스로 규칙을 만들고 새로운 지식을 얻는 방법이다. 데이터를 분석에 용이하도록 데이터를 가공하고, 핵심적인 특징을 추출하며, 결정함수를 통해 입-출력을 매핑하고 추론한다.
머신러닝의 성과를 측정하는 방법에는 목적함수를 얼마나 최적화하느냐가 있다. 목적함수란 학습 시스템이 달성해야하는 목표를 정의한 것으로, 대표적으로 오차함수가 있다. 오차함수는 학습 시스템이 출력한 값과 우리가 원했던 값의 차이로 정의되며, 이 차이를 최소화하는 것이 학습의 목표가 된다. 오차에도 학습에 사용한 데이터로 만들어진 오차가 있고, 학습에 사용되지 않은 새로운 데이터를 통해 얻어진 오차가 있다. 이러한 오차들을 일반화하여 추론하기 위해 여러 가지 방법이 사용되는데, 대표적으로 K-분절 교차검증법(K-fold cross validation)이 있다. 예를 들면 전체 데이터를 5개로 쪼개어 4개는 학습시키고 1개는 테스트 데이터로 하여 5번을 반복한 후에 오차를 평균내는 것이다.
머신러닝의 분야
머신러닝에는 데이터분석, 데이터표현 분야가 있다. 데이터 분석 분야에서는 분류, 회귀, 군집화 등을 다루며, 데이터 표현 분야에서는 특징 추출 등을 다룬다.
1. 데이터 분석: 분류(classfication)
분류문제란 입력 데이터가 어떤 클래스에 속하는지를 판단하는 문제이다. 학습의 목표는 각 데이터들이 결정규칙에 따라 분류되어 분류 오차를 최소화하는 최적의 결정경계를 찾는 데에 있으며, 학습 결과 결정경계(decision boundary) 혹은 결정함수(decision function)를 얻을 수 있다. 분류문제의 성능을 평가하는 방법에는 분류의 성공여부를 나타내는 분류율과 분류오차가 있다. 분류문제에 사용되는 대표적인 방법론은 베이즈 분류기, K-최근접이웃 분류기, 결정트리, 랜덤포레스트, SVM, 신경(MLP, CNN, LSTM) 등이 있다.
2. 데이터 분석: 회귀(regression)
회귀란 입력과 출력 사이를 매핑하는 함수를 말한다. 학습의 목표는 회귀오차를 최소화하는 최적의 회귀함수를 찾는 데 있으며, 학습 결과 회귀함수(regression function)를 얻을 수 있다. 회귀문제의 성능을 평가하는 방법에는 회귀오차가 있다. 회귀문제에 사용되는 대표적인 방법론은 선형회귀, 비선형회귀, 로지스틱회귀, SVM, 신경망(MLP, RBF, CNN, LSTM) 등이 있다.
3. 데이터 분석: 군집화(clustering)
군집화란 데이터를 서로 비슷한 몇 개의 그룹(클러스터)으로 나누는 문제이다. 군집화는 클러스터 정보가 주어지지 않은 상태에서, 새로운 데이터가 주어졌을 때 이 데이터가 어느 클러스터에 속할지 확률을 계산하여 확률이 가장 큰 클러스터로 할당한다. 학습의 목표는 최적의 클러스터 집합을 찾는 것이며, 학습 결과 클러스터 안에서는 유사도가 높고 클러스터끼리는 상이한 클러스터들의 집합을 얻을 수 있다. 군집화에 사용되는 대표적인 방법론은 K-평균 군집화, 계층적 군집화, 가우시안 혼합모델, 신경망(SOM)이 있다.
4. 데이터 표현: 특징추출(feature extraction, representation learning)
데이터는 학습하기 좋은 형태로 표현되어야 하기 때문에, 데이터 분석에 용이한 특징을 찾아내는 것이 중요하다. 학습 데이터들의 특징벡터 z를 추출하는 것이 특징 추출이다. 학습의 목표는 분석 목적에 따라 다를 수 있으며, 학습 결과 특징벡터 z를 추출하는 변환함수(embedding function)를 얻을 수 있다. 대표적인 방법론은 주성분분석(PCA), 선형판별분석(LDA), MDS, t-SNE 등이 있다.
정리하면 다음과 같다.
| 분야 | 학습목표 | 학습결과 | 방법론 |
| 분류 | 분류 오차를 최소화하는 최적의 결정경계 찾기 | 결정경계 혹은 결정함수 | 베이즈 분류기, K-최근접이웃 분류기, 결정트리, 랜덤포레스트, SVM, 신경(MLP, CNN, LSTM) 등 |
| 회귀 | 회귀오차를 최소화하는 최적의 회귀함수 찾기 | 회귀함수 | 선형회귀, 비선형회귀, 로지스틱회귀, SVM, 신경망(MLP, RBF, CNN, LSTM) 등 |
| 군집화 | 최적의 클러스터 집합 찾기 | 클러스터 집합 | K-평균 군집화, 계층적 군집화, 가우시안 혼합모델, 신경망(SOM) 등 |
| 특징추출 | 분석 목적에 따라 상이 | 변환함수 | 주성분분석(PCA), 선형판별분석(LDA), MDS, t-SNE 등 |
분류(Classfication)

분류 문제는 입력 데이터를 정의된 클래스로 구분하는 것이다. 지도학습을 통해 결정경계 혹은 결정함수를 찾아내고, 새로운 데이터들은 이를 통해 적당한 클래스로 분류가 된다. 분류를 다루는 문제는 베이즈 분류기, K-최근접이웃 분류기 등이 사용된다.
베이즈 분류기(Bayes classifier)
베이즈 분류기는 통계적인 접근방법으로, 베이즈 정리를 이용하여 분류하는 것이다. 새로운 x값이 주어졌을 때, x가 클래스1(C1)에 속할 것인가하는 문제는 사후확률 p(C1|x)로 구할 수 있다. 이러한 사후확률은 베이즈 정리에 따라 사전확률로부터 구할 수 있다.
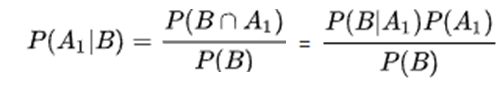
이에 따라 아래의 수식처럼, 클래스i에 대한 판별함수를 찾을 수 있다. 결정규칙은 판별함수의 값 중 가장 큰 값을 갖는 클래스 i를 찾는 것을 의미한다.
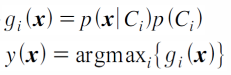
이러한 베이즈분류기를 이용할 때는 클래스별 분포 함수가 특정한 확률분포를 따른다고 가정한다. 예를 들면 가우시안 확률분포(정규분포)를 따른다고 했을 때, 평균과 공분산을 가지고 결정규칙을 만들 수 있다. 더 나아가 공분산의 형태에 따라서도 판별함수가 다른 형태를 보일 수 있다. 예를 들어 1) 모든 공분산이 동일하게 단위행렬의 상수배라고 가정한다면, 입력데이터와 클래스의 평균 간의 거리를 계산하여 거리가 가장 짧은 클래스에 해당 데이터가 속한다고 판별할 수 있다. 이를 최소거리 분류기(minimum distance classfier)라고 한다. 혹은 2) 모든 클래스가 동일한 공분산을 갖는다고 한다면 입력데이터와 클래스의 평균 간의 거리를 계산할 때 공분산을 고려하게 되는 마할라노비스 거리로 계산을 하게 된다. 입력 데이터 자체가 갖는 값의 범위나 분산에 의해 거리값이 왜곡될 수 있으므로 공분산을 사용하여 거리를 계산한다. 혹은 3) 공분산이 모두 다르다고 할 경우에는 결정경계가 곡선형태를 띄며, 계산값이 많아져서 성능이 떨어질 수 있다.
K-최근접이웃 분류기(K-Nearest neighbor classifier, K-NN)

최근접이웃 분류기는 데이터 x와 다른 데이터 사이의 거리를 모두 계산한 다음, x와 가까운 k개의 데이터를 뽑고 해당 데이터들이 가장 많이 속한 클래스에 x를 분류하는 것이다.
만약 k=1로 설정한다면 1개의 데이터만 의존하여 잡음이 생기며, 과다적합이 발생할 수 있다. 그렇다고 k를 많이 설정한다면 주변 데이터가 아닌, 전체 데이터로 추정하는 것이기 때문에 올바르지 않다. 따라서 여러 번 테스트해보고 적절한 k를 찾는 것이 중요하다. 또한 거리를 측정할 때에도 다양한 거리측정자가 있는데, 각각 거리측정자를 테스트하고 성능이 좋은 것을 선택한다.
K-최근접이웃 분류기는 비선형구조를 갖기 때문에 복잡한 비선형구조를 갖는 데이터분포에는 더 유리하다. 또한 베이즈분류기와 달리 확률분포모델을 미리 가정하지 않고 데이터집합을 이용하여 추정한다. 하지만 모든 데이터와의 거리를 측정하는 데 있어서 비용 부담이 있을 수 있다.
회귀(regression)
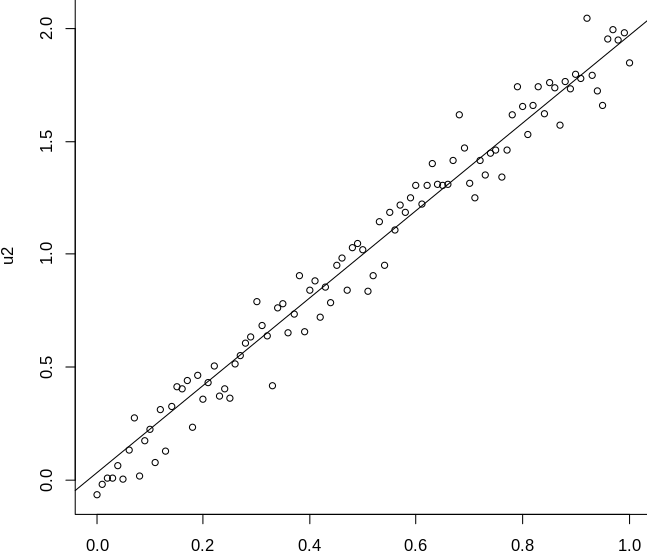
회귀는 입력변수와 출력변수의 매핑 관계를 찾는 것이다. 학습 데이터로 입력과 목표출력값이 주어지면 이를 분석하여 회귀함수를 찾는다. 이 때 목표출력값과 시스템 출력값의 차이인 예측 오차를 최소화하는 회귀함수의 매개변수를 찾는 것이 학습의 목표이다. 회귀를 다루는 문제에는 선형회귀, 로지스틱회귀 등이 사용된다.
선형회귀(linear regression)
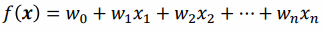
선형회귀는 1차식의 직선을 의미한다. 좋은 선형회귀 모델은 오차가 가장 작은 것이다. 이 때 사용하는 것이 오차의 제곱의 합으로 표현되는 오차함수이다. 위의 식에 따라 오차함수는 w1과 w0을 매개변수로 갖게 되며, 오차함수에 편미분을 적용하여 w1과 w0을 구할 수 있다. 이렇게 구한 w1과 w0 값을 이용하여 새로운 데이터를 입력하여 결과값을 예측할 수 있다.
주어진 데이터가 선형회귀로 표현될 수 있다면 좋겠지만, 그렇지 않은 형태인 경우 선형화(linearization) 과정을 거쳐야 한다. 예를 들어 지수형태라면 자연로그를 취해줄 수 있다. 그보다 더 복잡한 형태라면 다항회귀(polynomial regression), 비선형회귀(nonlinear regression)를 이용할 수 있다.
로지스틱회귀(logistic regression)
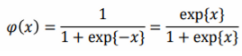
로지스틱 회귀는 분류 문제에 사용되는 회귀방법으로, 입력 값이 클래스에 속할 확률을 회귀분석으로 예측한 것이다. 로지스틱 함수는 0과 1사이의 실수값을 내며, 클래스에 대한 사후확률을 추정하는 형태로 표현된다. 위 로지스틱 함수 x에 ax+b 형태의 선형함수를 넣을 수 있다.
오즈비(odds ratio)는 입력값이 어떤 클래스에 속할지에 대한 확률의 비로 나타낸다. 이러한 오즈비에 자연로그를 취하면 로짓함수(logit function)이 되는데, 로짓함수는 결과적으로 ax+b 형태가 된다. 즉, ax+b>0이면 클래스A에, ax+b<0이면 클래스B에 속하는 판별 규칙을 만들어낼 수 있다.
군집화(clustering)
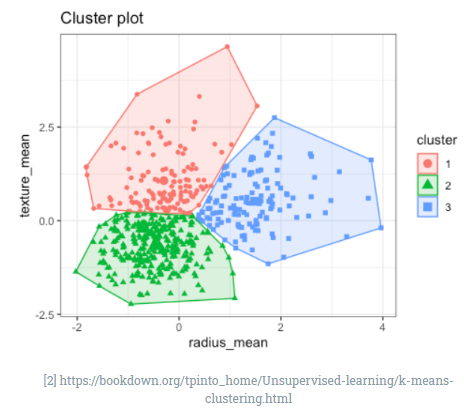
군집화란 데이터를 서로 교차하지 않는 여러 개의 집합(군집, 클러스터)으로 나누는 문제이다. 앞서 본 분류 문제는 학습 데이터가 클래스 레이블까지 주어진다면, 군집화는 데이터만 주어진다. 대표적인 방법론으로 K-평균 군집화, 계층적 군집화가 있다.
K-평균 군집화(K-means Clustering)
평균값을 이용하여 주어진 데이터 집합을 K개의 그룹으로 묶는 방법이다. 데이터 집합 중 임의로 K개의 벡터를 선택하여, 초기 대표벡터를 설정한다. 이후 나머지 데이터에 대해 K개의 대표벡터들과의 거리를 계산하여 해당 데이터와 대표벡터가 하나의 클러스터에 속하도록 레이블링한다. 새롭게 생성된 클러스터에 대해 대표 벡터를 다시 갱신하고, 다른 데이터에 대해서도 이 과정을 반복 수행한다. 수정 전의 대표벡터와 수정 후의 대표 벡터의 차이가 없다면 반복을 중단한다.
이러한 K-평균 군집화는 반복할 때 마다 지역 극소점을 찾는 것을 보장한다. 하지만 초기값을 어떤 것으로 세팅하느냐에 따라 반복 수가 늘어날 수 있다. 또한 최적의 클러스터 개수인 K를 설정하는 것 또한 중요하다.
계층적 군집화(Hierarchical Clustering)
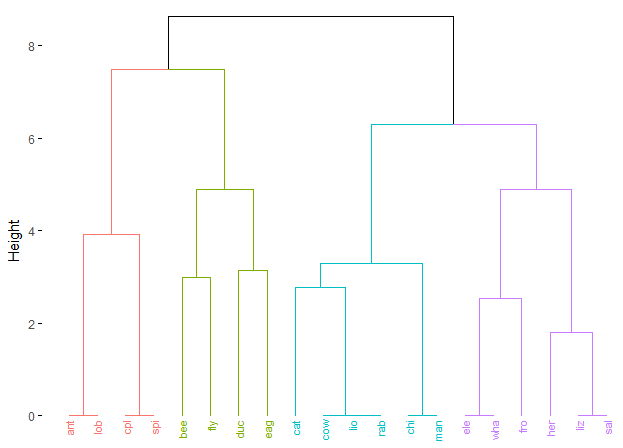
앞서 살펴 본 K-평균 군집화에서 K개의 클러스터를 결정할 때, 계층적 군집화 방법을 이용할 수 있다. 전체 데이터를 처음부터 배타적인 그룹으로 나누기 보다는, 큰 군집이 작은 군집을 포함하는 형태로 계층을 이룬 것이다. 보통 병합적 방법(bottom up) 방식이 사용되는데, 하나의 군집을 이루는 최소 군집에서 시작하여, 군집끼리 병합하여 더 큰 군집을 만들어나가는 것을 말한다.
군집을 묶을 때 거리를 계산하게 되는데, 가장 가까운 군집끼리 연결하는 최단연결법(single linkage), 가장 멀리 떨어진 군집끼리 연결하는 최장연결법(complete linkage), 군집의 평균 거리로 연결하는 중심연결법(centroid linkage) 등이 있다. 혹은 계층적인 군집화를 그림으로 표현한 덴드로그램(dendrogram)을 이용하여 거리가 증가하는 동안 클러스터 수가 늘어나지 않는 지점에서 클러스터의 개수를 결정할 수도 있다.
특징추출(feature extraction, representation learning)
특징추출이란 n차원의 입력 데이터를 m차원의 특징 벡터로 변환하는 것을 말한다. 소위 차원의 저주라는 말이 있다. 차원의 저주는 데이터의 차원이 커질수록 필요한 데이터 수가 증가하여 모델의 성능이 저하되는 것을 말한다. 따라서 특징 추출을 통해 분석에 불필요한 정보는 제거하고, 차원을 축소시킴으로써 효율을 향상시킬 수 있다.
특징추출에는 변환함수(embedding function)이 사용되며, 변환함수는 선형 변환과 비선형 변환으로 나뉜다.
선형 변환은 n차원의 열 벡터에 변환행렬 W를 곱하여 m차원의 특징을 획득하는 방법이다. 특징벡터가 원하는 분포를 갖도록 W를 조정하면서 찾는다. 주성분 분석법, 선형판별 분석법이 이에 해당된다. 선형 변환은 데이터 특성에 의존하지 않고 일반적으로 사용될 수 있다. 앞서 설명한대로 선형변환행렬 W를 이용하는데, 특징 벡터의 값은 원 데이터를 W의 열 벡터 위로 사영하여 얻은 값이다. 다시말해, 주어진 데이터를 변환행렬 W에 의해 정해진 방향으로 사영하여 저차원의 특징을 얻는 것이다. 이러한 변환행렬을 어떻게 조절하느냐에 따라 분포가 다르게 나타날 수 있으므로, 분석 목적에 맞추어 설정하는 것이 중요하다. 선형변환에는 대표적으로 주성분분석법과 선형판별분석법이 있다.
반면 비선형 변환은 비선형함수를 이용하여 n차원의 벡터를 m차원의 특징 벡터로 매핑시킨다. 대표적으로 표현학습(representation learning)이 있다. 표현학습은 신경망을 통해 학습을 하여 상위 레벨로 갈 수록 추상화된 특징으로 추출하는 것이다.
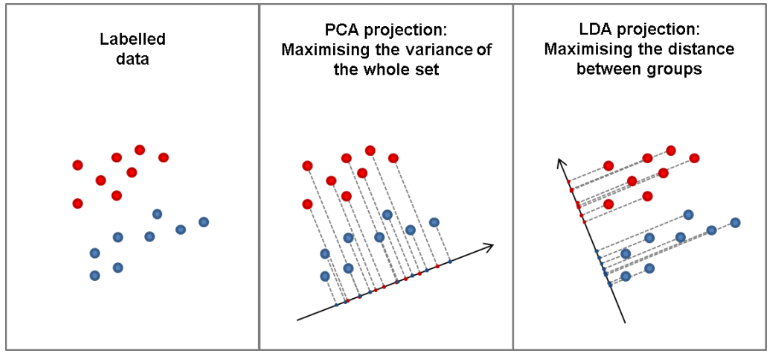
주성분분석법(Principal Component Analysis, PCA)
주성분분석법은 변환 전의 데이터가 가지고 있는 정보를 최대한 유지하는 방향, 즉 데이터의 분산이 가장 큰 방향으로 선형 변환을 수행하는 것이다. 적절한 분산과 방향을 찾기 위해서는, 고유치분석을 통해 공분산행렬의 고유치와 고유벡터를 찾고 고유치가 가장 큰 값부터 순서대로 대응하는 고유벡터를 찾아 행렬 W를 구성해야 한다.
주성분분석법은 데이터 분석에 특별한 목적이 없는 경우 가장 합리적인 방법이 될 수 있다. 하지만 비지도학습이기 때문에 분류 문제에서는 정보의 손실이 발생할 수 있으며, 선형 변환이기 때문에 비선형 구조를 반영하지 못한다는 한계가 있다.
선형판별분석법(Linear Discriminant Analysis, LDA)
선형판별분석법은 클래스의 레이블 정보를 활용하는 지도학습을 통해 분류 문제를 다루고, 클래스 간 판별이 잘 되는 방향으로 차원을 축소한 것이다. 선형판별분석법에서는 클래스 간의 산점행렬과 클래스 내 산점행렬을 사용하는데, 간단하게 말하자면 클래스 간에는 멀리 떨어져 있되 클래스 내부의 분산은 줄이는 것이다. 이러한 목적함수를 최대로 하는 변환행렬 W를 구하는 것이다. 이후에는 주성분분석법과 마찬가지로 고유치 분석을 통해 고유치가 가장 큰 값부터 순서대로 대응하는 변환행렬 W를 구성한다.
선형판별분석법은 주성분분석법과 마찬가지로 비선형 구조를 반영하지 못한다는 한계가 있다. 또한 입력 데이터 수가 입력 차원보다 작다면 클래스 내 산점행렬을 구하는 데 어려움이 있을 수 있다.
거리 기반 차원 축소 방법
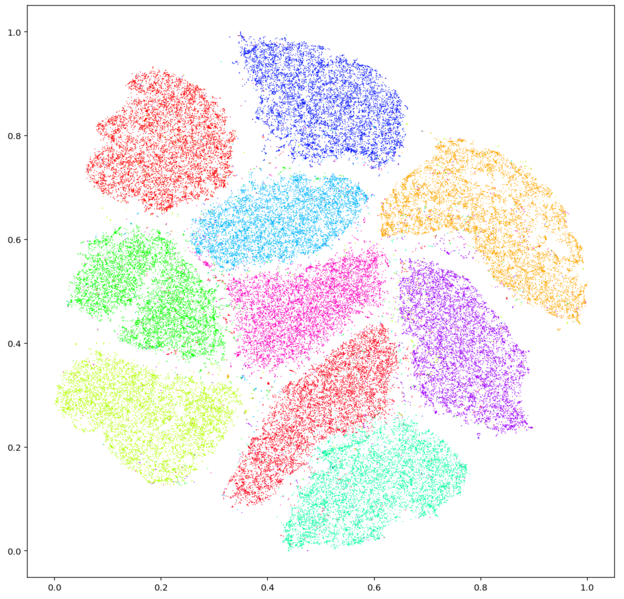
거리 기반 차원 축소 방법은 두 개의 데이터 사이의 거리를 유지하는 방향으로 차원을 축소하는 것이다. 다만 거리를 어떻게 적용하느냐에 따라 다양한 방법이 존재한다. 다차원 척도법(multi-dimensional Scaling: MDS)은 유클리디안 거리를 사용하고, t-SNE(t-Stochastic Neighbor Embedding)는 확률밀도함수를 이용하여 거리를 정의한다.
거리 기반 차원 축소 방법은 입력데이터와 특징 데이터간의 매핑 함수를 정의하지 않기 때문에 새로운 데이터에 대해서는 대응값을 알 수 없다. 때문에 데이터 시각화 용도로 주로 사용된다.
앙상블 학습(Ensemble Learning)
앙상블 학습이란 간단한 학습기를 여러 개 결합하여 성능을 좋은 학습기를 만드는 방법이다. 앙상블은 프랑스어로, '함께, 동시에, 한꺼번에, 협력하여' 등을 의미하는 부사이다. 간단한 학습기를 사용하면 구현은 쉬워도 성능이 떨어질 수 있으며, 복잡한 학습기는 성능이 좋지만 구현하기가 어렵다. 따라서 학습기를 결합하여 복잡한 학습기와 유사한 성능을 내도록 구현할 수 있다.
이를 위해서는 어떤 학습기를 선택해야 할지, 어떻게 결합해야할지를 결정해야 한다. 알고리즘이 다른 학습기를 사용하거나, 파라미터만 변형하거나, 학습 데이터 집합을 차별화하는 방법이 있다. 이렇게 나온 학습 결과를 모두 고려하여 최종 결과를 만들거나, 단계별로 결합하는 방법이 있다.
배깅(bagging)
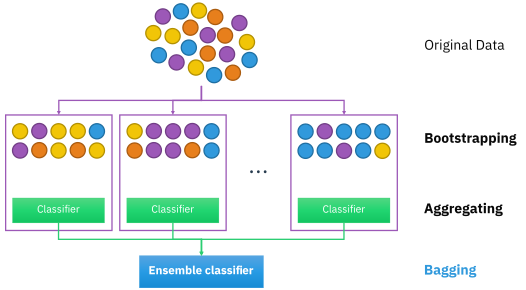
배깅은 부트스트랩을 적용한 방식이다. 부트스트랩은 제한된 데이터 집합으로 학습과 평가를 동시에 수행하는 리샘플링(resampling) 기법이다. 리샘플링은 학습 때마다 학습 데이터를 새로 생성하지 않고, 주어진 전체 학습 데이터로부터 일부 집합을 추출하여 학습시키는 것이다.
배깅의 학습과정은 다음과 같다. 우선 전체 데이터 집합을 준비하고, 그 중 학습시킬 부분집합을 만든다. 이를 학습시켜 파라미터를 찾고, 판별함수를 얻는다. 이를 반복하여 서로 다른 M개의 학습기를 생성하고 결합하여 최종 판별함수를 얻는다.
부스팅(boosting)
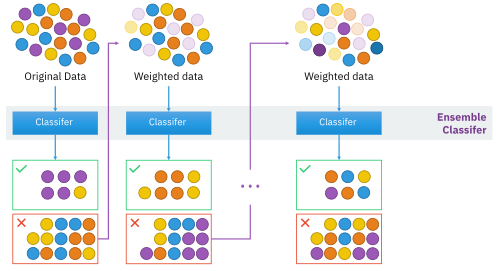
부스팅은 단계적으로 학습을 수행하고 결합하여 성능을 증폭시키는 방법이다. 이전에 학습한 결과를 다음 학습기에 제공하여, 이전 학습기의 결점을 보완하는 형태이다.
가장 처음에 제안된 것은 필터링에 의한 부스팅 방법(boosting by filtering)이다. 필터링(filtering)은 각 학습 때마다 새로운 데이터를 생성하고, 이미 학습이 완료된 학습기에 적용하여 제대로 처리되지 못한 데이터만 골라내어 학습하는 방법이다. 하지만 이 경우 학습을 할 때 마다 학습데이터의 일부만 학습이 되는 형태이기 때문에, 데이터 규모가 매우 커야 하는 단점이 있다.
이를 보완한 것이 Adaboost 알고리즘이다. Adaboost는 같은 데이터 집합을 반복해서 사용하고, 학습할 때마다 데이터의 가중치를 조정하여 학습의 변화를 만드는 것이다. 실제 출력과 목표 출력의 차이를 반영하는 오분류율 정의하고, 오분류율을 사용하여 오분류율이 작을 수록 분류기의 중요도가 커지는 방향으로 각 분류기의 중요도 값을 얻는다. 이후 각 데이터의 가중치를 수정하는데, 제대로 분류했다면 학습 가중치를 낮추고 제대로 분류하지 못했다면 학습기의 가중치를 높여준다. 이렇게 학습기가 모두 학습되면, 결합하여 최종 판별함수를 얻는다.
보팅(voting)
보팅은 M개의 학습 결과를 반영한 결과를 얻는 방법이다. 분류 문제에서 사용되는데, 분류기가 출력하는 클래스 레이블 중 가장 많은 클래스 레이블을 찾아주는 방식이다. 여기에 가중치를 부여하여 결정할 수도 있다. 보팅은 0 혹은 1로 출력을 내거나, 0~1 사이의 실수 값으로 출력을 낼 수도 있다.
캐스케이딩(cascading)
여러가지 복잡도를 갖는 다양한 학습기를 순차적으로 결합하는 방법이다. 첫 학습기에서 오류나 신뢰도 기준을 만족하지 못했다면, 다음 학습기에서 학습을 시키는 방식이다. 앞단에는 간단한 학습기를, 뒷단에는 복잡한 학습기를 배치하여 계산시간을 줄이고 성능을 보장할 수 있다.
전문가 혼합(mixture of experts)
복수개의 학습기를 가중합 하여 결합하는 방법이다. Adaboost와 비슷해보이지만, 전문가 혼합에서는 주어진 입력 데이터 x에 따라 가중치를 변동시킨다는 점에서 차이가 있다.
결정 트리(decision tree)
입력값 x는 함수 f를 거쳐 출력값 y를 내는데, 이 때 함수 f를 트리형태로 표현한 것이 결정 트리이다. 결정트리를 이용하면 어떤 과정으로 출력값 y가 나왔는지 설명하기 용이하며, 학습을 통해 자동으로 생성된다.
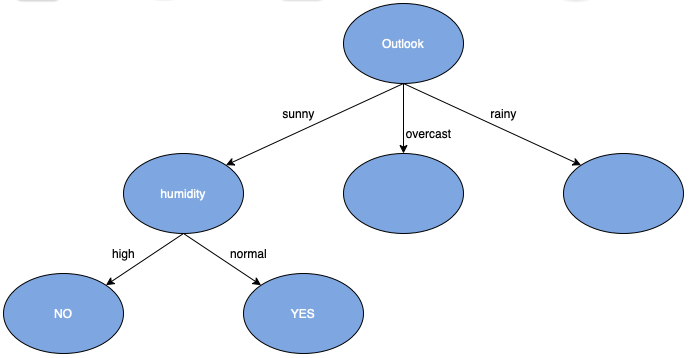
결정트리를 만들기 위해서는 처음에 루트노드 속성을 무엇으로 할지 선택해야 한다. 이후 가지를 생성하여 자식노드 속성을 또 다시 선택하고, 자식노드들이 리프노드를 만들어내면 더 이상 분할할 필요가 없는 상태에 이르게 된다. 이 때 어떤 속성을 선택할 것인지 결정하는 것이 중요하다. 여기에 사용되는 평가 기준으로는 지니 평가지수(Gini criterion)가 대표적이다. 지니 평가지수는 각 노드에 할당된 클래스 레이블이 얼마나 다른지를 측정하는 지니 불순도(Gini Impurity)를 이용한다. 지니 평가지수는 각 자식노드의 지니 불순도에 가중치(부모노드에 속하는 데이터 개수)를 곱한 합으로 계산할 수 있다. 지니 평가지수 외에 데이터 분할 전후의 혼잡도를 나타내는 엔트로피를 이용한 정보 이득(information gain), 분산의 가중 평균을 이용한 분산 감소량(reduction invariance), 부모-자식 노드 간 차이의 통계적 유의성을 활용한 Chi-square 등이 사용된다.
결정 트리를 이용하여 깊이를 깊게 하면 우리가 원하는 결과에 도달한다고 생각할 수 있지만, 반드시 그렇지는 않다. 학습이 끝난 상태임에도 불구하고 우리가 구하고자하는 결정경계와 모양이 다를 수 있고, 노이즈까지 완벽 학습한 과다적합 문제가 발생할 수 있다.
이를 해결하기 위해서는 노드 분할을 조기 종료(early stopping)하는 방법, 불필요한 노드를 제거(pruning)하는 방법 등이 있다.
랜덤 포레스트(random forest)
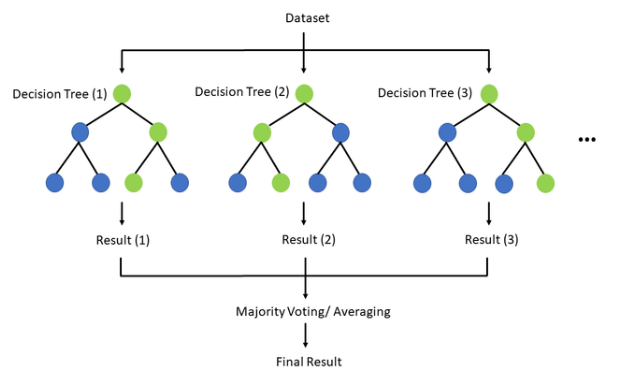
랜덤 포레스트는 결정 트리와 앙상블 학습기법(리샘플링)을 더한 방법으로, M개의 결정 트리를 학습하고 결합한다. 결정 트리의 과다적합 문제를 해소할 수 있는 방법 중 하나이다.
랜덤 포레스트를 만들기 위해서는 먼저 전체 데이터 집합 중 부분 집합의 크기를 정한 후, 부분 집합별로 학습을 통해 결정 트리를 만든다. 결정트리를 통해 얻어진 판별함수를 결합하여 최종 판별함수를 찾는다.
서포트 벡터 머신 (support vector machine, SVM)
선형분류기는 선형 판별함수를 바탕으로 분류를 하는 시스템이다. 직선으로 표현되기 때문에 복잡도는 낮고 과다적합의 문제를 피할 수 있으나, 분류 성능이 좋지 못하다는 단점이 있다. 반면 비선형 분류기를 사용한다고 하더라도, 학습에 사용되지 않은 데이터로 분류 시 오차가 발생할 수 있다. 이를 일반화 오차라고 한다.
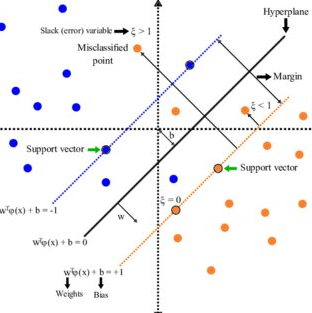
따라서 선형분류기를 사용하되 일반화 오차를 최소화할 수 있는 방향으로 설계된 것이 SVM(support vector machine)이다. SVM은 데이터 마이닝 기법 및 인공지능에 쓰이는 대표적인 알고리즘이다. SVM은 데이터를 분류하는 초평면(hyperplane)을 구하는 알고리즘으로, 서포트 벡터와 마진이라는 개념을 사용한다. 서포트 벡터는 대표하는 군집의 최전선에 존재하는 벡터이며, 마진은 결정경계와 가장 가까운 데이터와 결정경계의 거리를 말한다.
SVM에서는 일반화오차를 줄이기 위해 클래스 간의 간격을 최대로 해야하므로, 마진을 최대화 해야 한다. 즉, SVM을 학습시킨다는 것은 마진을 최대화하기 위한 목적함수를 정의한다는 것이다. 여러 수학적 기법을 사용하면 결과적으로는, 서포트 벡터에 해당하는 데이터와 라그랑주 승수값만 있으면 목적함수를 얻을 수 있다.
이러한 서포트 벡터 머신은 선형분류기 이기 때문에, 비선형 데이터의 분류 문제를 대응하기 위해 오분류를 허용하는 슬랙변수(slack variable)를 활용할 수 있다. 슬랙변수는 잘못 분류된 데이터로부터 해당 클래스의 결정 경계까지의 거리를 의미한다.
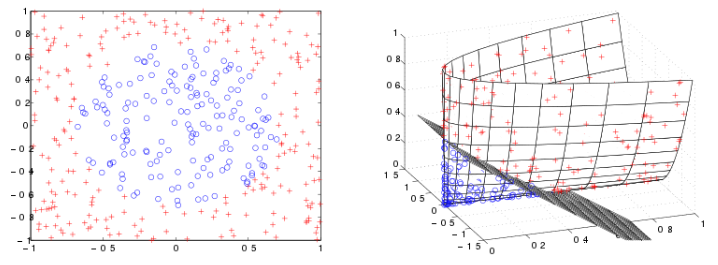
커널법은 이러한 문제를 더 적극적으로 해결해줄 수 있다. 커널법을 사용하면 저차원의 입력을 고차원의 공간으로 매핑시킬 수 있는데, 고차원의 공간에서는 간단한 선형 분류기로 문제를 해결할 수 있다. 또한 커널 함수를 사용하면 차원 확대에 따른 계산량 증가의 문제도 해소할 수 있다. 커널함수(kernel function)는 고차원 매핑함수를 내적하여 2차원의 형태로 계산하도록 도와준다. 이러한 커널 함수는 선형 커널, 다항식 커널, 시그모이드 커널, 가우시안 커널 등으로 분류되며 목적에 따라 원하는 커널 함수를 선택하면 된다.
인공신경망(Artificial neural networks)
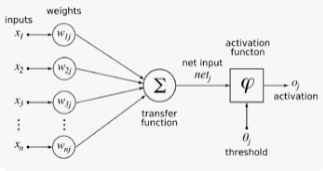
인공신경망은 연결주의적인 접근 방법으로, 인간의 신경회로망을 모델링한 수학적 함수이다. 인공신경망은 데이터를 이용하여 학습을 수행하고, 매핑함수를 스스로 찾는 학습 능력을 갖춘다. 또한 인공신경망은 어떤 형태의 함수도 표현할 수 있으며, 데이터에 대해 일반화된 규칙을 찾을 수 있기 때문에 새로운 데이터를 처리하는 데 유리하다.
인간의 신경망에서 수상돌기는 자극을 받아들이는 역할을 수행한다. 이 자극이 세포체를 통해 모아지면 활성화되어, 축색을 따라 다른 세포로 연결된다. 이 때 시냅스를 통해 어느 정도의 자극을 전달할 지 조정이 된다. 이러한 신경세포는 계층구조로 이루어져 있다. 인공신경망은 이를 본 뜬 것으로, 아래 세 가지로 구성되어 있다.
1. 인공신경세포(뉴런)
인공신경세포는 하나의 신경세포가 수행하는 기능을 수학적 함수로 정의한 것이다. 입력 값에 대하여 입력값 마다 주어지는 가중치를 곱하여 더하고, 활성화 함수(activation function)를 사용하여 역치 수준에 맞추어 출력을 결정한다. 이 때 활성화 함수는 인공신경세포의 특성을 결정하게 된다. 활성함수는 계단함수, 부호함수, 선형함수, 시그모이드 함수, 하이퍼탄젠트 함수, ReLU 함수가 있다. 그 중 미분이 가능한 시그모이드함수, 하이퍼탄젠트 함수를 자주 사용하며, 최근에는 ReLU 함수도 많이 사용된다고 한다.
2. 신경망 구조(연결구조)
신경세포들이 서로 정보를 연결하는 구조도 중요하다. 대표적으로는 다층 전방향 신경망(multi-layer feed forward neural network)을 사용하는데, 입력층과 출력층 간 은닉층을 두는 형태이다. 입력층에서 출력층으로 정보가 흘러가며, 각 층간의 연결은 있지만 층 내 연결은 없는 형태이다. 층수에 따라 구분을 하기도 하는데, 은닉층이 없드면 단층 신경망(single layer), 여러 층이 있으면 다층 신경망 혹은 심층 신경망(multilayer)이라고 부른다. 또한 정보의 흐름에 따라 구분되기도 하는데, 앞서 입력→출력으로 이어지는 전방향(fee-forward) 신경망, 출력이 입력으로 다시 제공되거나 같은 층 간의 연결이 있는 등의 형태인 회귀(recurrent) 신경망(RNN)이 있다.
3. 학습 알고리즘
인공신경망에서의 학습은 신경세포들 간 연결 강도(가중치)를 조절한다. 보통 현재 가중치에 가중치 변화량을 더하여 학습 후 가중치를 만드는 형태로 조정되며, 반복적으로 이를 수행하며 점점 원하는 기능에 근접해간다. 학습에는 지도학습, 비지도학습, 강화학습 등의 방법이 사용된다.
다음은 인공신경망 모델이다.
M-P 뉴런
1943년 인공신경망에 대한 첫번째 연구로 등장한 모델이다. 입력값과 가중치를 곱하여, 그것의 합을 구하고 계단함수를 사용하여 0과 1로만 출력하는 함수가 정의되었다.
퍼셉트론(perceptron)
1958년 M-P 뉴런을 여러 개 결합하여 계단함수를 사용한 네트워크 형태의 신경망으로, 패턴인식을 수행하는 최초의 신경망이다. 단층 신경망으로 전방향이며, 완전 연결되어 있다. 학습은 지도학습을 사용하여 0과 1의 이진 입출력값만 제공된다. 가중치를 결정하는 데 있어, 목표출력과 실제출력을 비교하여 결정하며, 여기에 학습률을 통해 학습의 정도를 조절할 수 있다.
하지만 퍼셉트론은 비선형 결정경계를 표현할 수 없다. XOR문제를 해결할 수 없음이 지적되었고, 이를 해결할 수 있는 다층 퍼셉트론 개념이 등장하게 되었다.
다층 퍼셉트론(multi-layer perceptron)
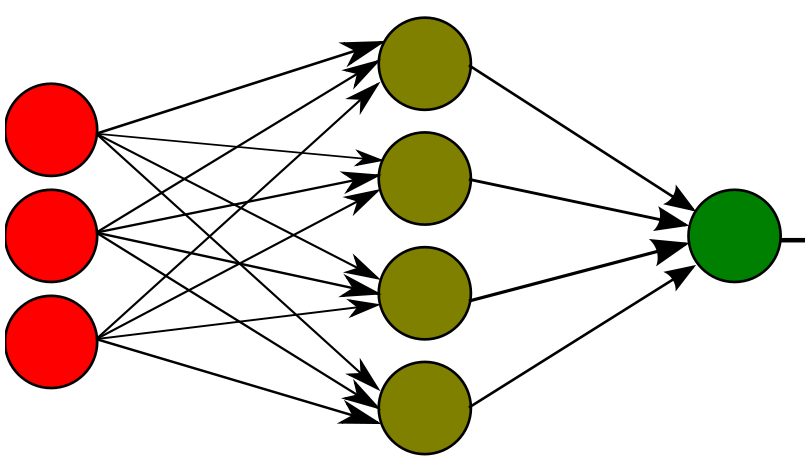
다층 퍼셉트론은 1개 이상의 은닉층을 갖는 퍼셉트론이다. 출력층에는 다른 함수를 사용하더라도, 은닉층에서는 기본적으로 시그모이드 함수나 하이퍼탄젠트 함수를 사용한다. 은닉층이 추가된 형태이므로 다층 신경망이며, 전방향이고 완전 연결되어 있다. 또한 '오류 역전파 알고리즘(error back propagation learning algorithm)을 사용하여 입력층-은닉층, 은닉층-출력층 간의 가중치를 조절할 수 있는 지도학습을 한다.
다층 퍼셉트론은 활성함수 뿐 아니라 가중치의 정도, 은닉노드의 개수에 따라 매우 다양한 형태의 그래프를 갖는다. 그만큼 표현능력이 뛰어나며, 비선형 결정경계의 분류문제를 해결할 수 있다.
딥러닝(deep learning)
심층 신경망이란 많은 수의 은닉층을 가진 다층 퍼셉트론을 의미한다. 이러한 심층 신경망을 기반으로 한 머신러닝 분야가 바로 딥러닝이다. 은닉층을 많이 갖게 되면 더 효율적인 표현이 가능하며, 심층 신경망은 특징 추출과 분류 과정을 한꺼번에 학습한다. 다만 학습이 어렵다는 단점을 갖고 있는데, 딥러닝에서는 이를 해소하기 위한 여러 장치를 가지고 있다.
지역 극소(local minima) 문제
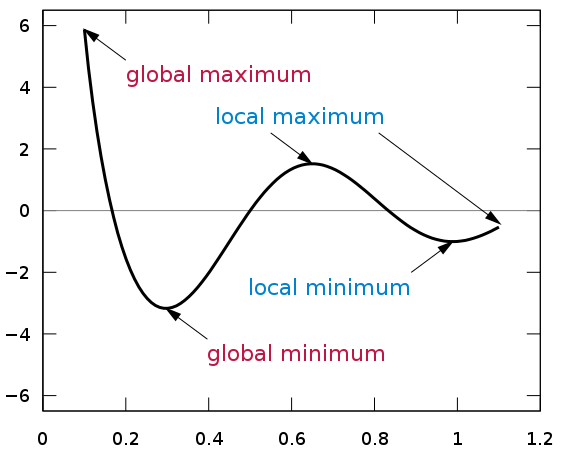
기울기 강하 학습법을 통해 학습을 진행할 경우 오차가 충분히 작지 않은 지역을 극소점으로 착각하여 학습이 멈추는 문제가 발생할 수 있다. 이를 해결하기 위해 모의담금질(simulated anneling) 기법으로 학습률을 적절히 조절할 수 있다. 또한 확률적 기울기 강하(stochastic gradient descent) 학습법을 통해 한 번에 하나의 샘플만 이용하여 불안정하게 학습시킴으로써 지역 극소에 빠지지 않도록 도움을 줄 수도 있다.
느린 학습(slow learning) 문제
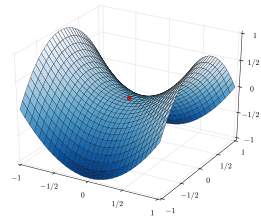
기울기 강하 학습 중 오차함수의 학습곡선에서 평평한 플라토(plateau) 구간을 만날 수 있는데, 이 구간에서는 학습이 느리게 진행된다. 오차함수는 이러한 플라토를 만드는 안장점(saddle point)를 무수히 많이 갖고 있다. 또한 오류 역전파 시 활성함수의 미분값을 사용하는데, 이 경우 오차신호가 출력층에서 입력층으로 내려오면서 점점 약해지며 학습이 느려지게 된다.
이를 해결하기 위해 시그모이드, 하이퍼탄젠트 함수 대신 ReLU, softplus, leaky ReLU 등을 사용하는 방법이 있다. 또한 처음에 가중치를 초기화할 때 셀 포화가 일어나지 않도록 작은 값에서 시작하고, 가중치를 랜덤하게 설정한다. 혹은 기울기 강하 학습법에서 변화량 수정 시 이전 학습의 움직임을 반영하도록 모멘텀(momentum)을 계산해주거나, 가중치 변화량의 누적합을 활용하여 변화폭에 따라 학습률을 조정하는 방법도 있다.
과다 적합 문제
과다적합은 학습데이터의 노이즈까지 학습하여 일반화 성능이 떨어지는 것을 말한다. 이를 해결하기 위해 학습을 하는 동안 검증오차를 계산하여, 검증오차가 증가하는 구간에서 종료하는 조기종료(early stopping)방법이 있다. 혹은 오차함수에 정규항(regularization term)을 추가하여 가중치가 지나치게 커지는 것을 방지할 수 있다. 학습을 할 때마다 은닉 노드의 일부를 랜덤하게 제외시키는 드롭아웃(dropout)이나, 학습 데이터에 인위적인 변형을 통해 추가 데이터를 생성하여 충분한 학습 데이터를 확보하는 방법도 있다.
다음은 심층 신경망 모델이다.
합성곱 신경망(CNN, convolutional neural network)
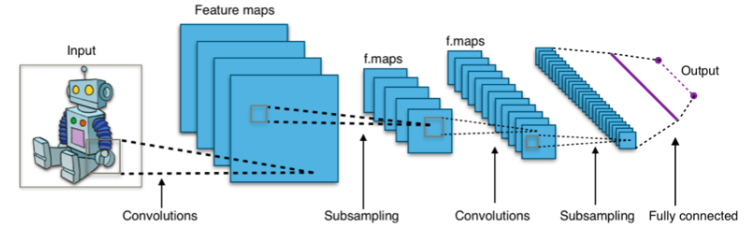
합성곱 신경망은 인간의 시각 피질의 정보 처리 기제로부터 영감을 받은 것으로, 영상 데이터 처리에 적합한 모델이다. 합성곱 신경망에서 인공신경세포는 콘볼루션층, 풀링층, 완전연결층 3가지의 층으로 구성되어 있다.
콘볼루션(convolution)층은 주어진 2차원의 입력에 콘볼루션 연산을 사용하여 필터를 적용하고 활성함수(ReLU)를 사용하여 특징 맵을 만든다. 특정한 연결에만 연결되어 부분 연결(local connection)이라고 표현된다. 필터를 적용하게 되면 가장자리의 값을 구할 수 없기 때문에, 가장자리를 0으로 임의로 생성하여 출력값을 내는 것을 패딩(zero padding)이라고 한다. 또한 입력이 다중채널을 형성할 경우, 다중채널마다의 값을 모두 더하여 계산한다. 여러 필터를 적용해야 한다면, 필터의 개수만큼 특징맵이 형성된다. 혹은 필터를 움직이는 보폭(stride)을 조정하여 특징맵의 크기를 변경시키거나, 다중 필터를 적용하여 데이터 차원을 축소시킬 수 있다. 즉, 입력크기, 채널수가 입력층에서 주어지면 콘볼루션층에서는 필터의 크기, 보폭, 패딩에 따라 특징맵이 결정된다.
풀링(pooling)층에서는 풀링연산을 통해 특징맵의 크기를 줄여준다. 사이즈와 보폭을 정하여 나누어 최대값(max pooling) 혹은 평균값(average pooling)을 계산하여 풀링값을 결정한다. 풀링층을 통해 특징맵의 크기를 작게 만들고, 데이터의 작은 위치 변화도 수용할 수 있게 된다.
신경망 구조(연결구조)는 레이어를 이루는 층상 구조이다. 입력층은 2차원의 그리드 형태로 다중 채널을 이루고 있으며, 콘볼루션층과 풀링층은 2차원의 특징맵 형태에 다중 필터를 두고 있다. 특징맵은 입력의 한 부분만을 연결하고 있으며, 연결을 위해 가중치를 사용하는데 이 가중치는 공유되고 있기 때문에 일반화 성능을 높이는 데 도움이 된다. 완전연결층은 다층퍼셉트론 구조를 가지고 있다.
학습 알고리즘은 오류 역전파 알고리즘을 사용하며, 여기에 학습 성능을 향상시키기 위해 앞서 모멘텀, 드롭아웃 등의 테크닉을 더한다.
순환 신경망(RNN, recurrent neural networks)
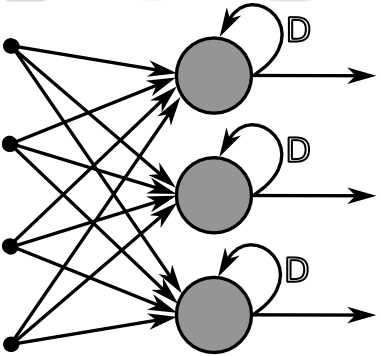
순환 신경망은 음성, 문장, 동영상 같은 순서가 있는 데이터를 다루는 데 사용되는 모델이다. 순환신경망은 은닉노드 사이에 순환이 존재하여, 직전 은닉노드와 가중치를 고려하여 은닉노드를 결정하게 된다. 따라서 이전 출력이 현재의 입력으로 사용되며, 계산이 순차적으로 이루어진다는 특징이 있다. 은닉노드는 활성함수로 하이퍼탄젠트 함수를 사용하고, 출력노드는 활성함수로 softmax 함수를 사용한다.
입출력 관계에 따라서도 다양한 모델이 존재하며 활용되는 분야가 상이하다. 입력을 1개 받아서 출력을 여러 개 만들어내는 모델은 이미지 설명 및 묘사에 적합하다. 반대로 입력을 여러 개 받아 출력을 1개 만들어내는 모델은 필기인식, 감정분류에 적합하다. 이러한 순환 신경망은 은닉층을 여러개 사용하는 다층 RNN과, 앞쪽과 뒤쪽의 정보를 순차적으로 처리하며 정보를 전달하는 양방향(bidirectional) RNN으로도 분류할 수 있다.
순환 신경망은 지도학습으로 이루어지며, 목표출력값과 실제출력값의 차이의 합인 손실함수 L(w)를 최소화하는 방향으로 학습이 이루어진다. 이를 위해서는 시간 역전파 학습 알고리즘(BPTT, Backpropagation Through Time)이 사용된다. 하지만 시점과 시점의 길이(timestep)가 길어질수록 마찬가지로 기울기 소멸 문제가 발생할 수 있다. 이를 개선하기 위해 만들어진 모델이 LSTM과 GRU이다.
LSTM(Long Short Term Memory)
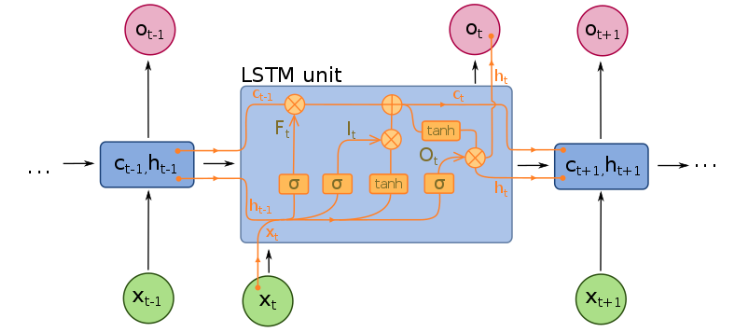
순환 신경망 모델은 시간의 흐름에 따라 이전에 들어왔던 입력이 점점 사라지는 장기 의존성 문제(long-term dependency)를 갖고 있다. 시간의 흐름에 의존하기 보다, 게이트를 활용하여 기존의 입력 정보를 기억하고 그 정도를 조절하는 모델이 LSTM이다.
LSTM은 망각게이트(forget gate)와 입력게이트(input gate)를 통해 이전 셀의 정보를 어느정도 잊어버리고, 어느정도 추가할지를 조정한다. 망각게이트는 활성함수로 시그모이드함수를 사용하며, 입력게이트는 하이퍼탄젠트 함수를 사용한다. 이를 통해 셀 상태를 갱신하고, 출력 계산 부분에서는 출력 게이트(output gate)를 이용하여 셀의 출력과 출력층의 결과값을 계산한다. 출력게이트는 활성함수로 하이퍼탄젠트 함수를 사용하며, 출력층의 결과를 계산할 때는 softmax 함수를 사용한다.
GRU(Gated Recurrent Unit)
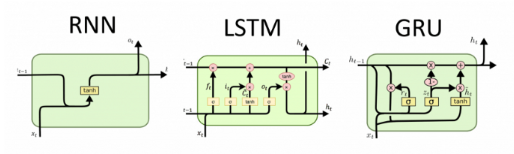
GRU는 LSTM을 간소화한 것으로, LSTM의 셀 내부 상태(셀이 기억하고 있는 내용)를 고려하지 않는다. 또한 입력게이트와 망각게이트를 하나로 합쳐 갱신게이트(update gate)로 표현하며, 리셋 게이트(reset gate)를 통해 출력을 어느정도로 받아들일지 조정한다.
딥러닝의 응용
컴퓨터 비전(Computer Vision)
딥러닝은 컴퓨터 비전에도 활용할 수 있다. 영상을 입력으로 받고 영상 내 객체와 의미적 정보를 분석하거나, 영상을 입력 받아 원하는 형태로 변환하거나, 랜덤 노이즈 혹은 자연어 문장으로 새로운 영상을 생성할 수도 있다.
AlexNet은 2개의 CNN과 콘볼루션층, 완전연결층으로 구성되어 영상 속 객체를 분류한다. VGG Net은 다양한 층수의 여러 가지 버전을 제공한다. GoogLeNet은 인셉션 모듈을 사용하여 필터를 다양하게 사용하고 차원을 줄인다. ResNet은 잔차(residual) 모듈을 사용하여, 매우 깊은 층을 갖는 네트워크여도 성능을 저하시키지 않고 학습을 할 수 있다. R-CNN은 영상 내 객체를 검출할 때, 입력에 대해 객체가 있을 만한 후보 영역을 찾고 판독한다. Faster R-CNN은 R-CNN의 병렬처리 등을 추가하여, 속도를 빠르게 개선시켰다. YOLO(You Only Look Once) 모델에서는 bounding box를 활용하여 실시간 영상에서 객체를 탐지할 수 있다.
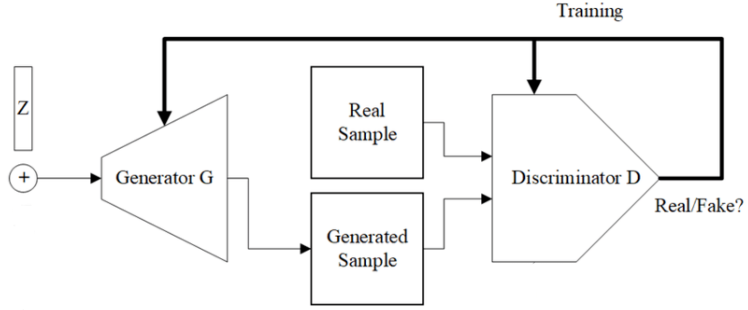
영상을 변환하는 데 있어서는, 기본적으로 오토인코더 모델이 사용된다. 오토인코더 모델은 영상을 입력받아 입력크기를 줄이는 인코더 과정을 수행하고, 이를 디코더 과정을 통해 복원하여 새로운 영상을 만들어낸다. U-Net은 CNN을 기반으로 한 오토인코더 모델로, U자형 구조를 가지고 있다. GAN(Generative Adversarial Networks) 모델은 Generator와 Discriminator 이라는 두 가지 네트워크로 구성하여, 랜덤 입력으로부터 이미지를 생성받아 진짜 영상처럼 만들도록 학습하고 만들어진 영상은 진짜와 가짜를 잘 구분할 수 있도록 학습한다. GAN을 변형시킨 모델도 다수 등장하는데, Cycle GAN, CoGAN, Progressive GAN, Style GAN 등 다양하다.
Show and Tell 모델에서는 영상처리를 위해 CNN을, 자연어처리를 위해 RNN을 사용하여 영상에 대해 자연어를 출력할 수 있다. Show, Attend and Tell 모델은 단어에 해당하는 영상 부분에 Attention이 가해지도록 처리된다.
자연어처리(NLP, Natural Language Processing)
자연어처리란 컴퓨터로 자연어(인간의 언어)를 이해하고, 번역하고, 조작하기 위한 분야이다. 자연어처리를 통해 음성 신호를 처리하거나, 스피커나 챗봇 등을 통해 대화를 하거나, 텍스트를 입력받아 분류/번역/요약할 수 있다.
자연어를 처리하기 위해 우선 텍스트 말뭉치(text corpus)를 수집한다. 이후 컴퓨터가 이해할 수 있도록 전처리를 하는데, 말뭉치를 토큰으로 나누고 데이터 분석에 방해되는 노이즈를 제거하는 정제과정(cleaning), 표현 방법이 상이한 단어들을 통합하는 정규화과정(normalization)을 거친다. 이후 머신러닝이 다룰 수 있는 숫자로 표현을 하는데, 단어를 고유한 정수로 매핑한 원핫인코딩(one-hot encoding) 방식, 단어의 빈도 수를 고려한 Bow(Bag of Words), 단어의 빈도수와 문서의 빈도를 함께 고려한 TF-IDF(Term Frequency-Inverse Document Frequency) 등을 사용할 수 있다. 이후 단어들 간의 의미, 유사도 등을 분석하기 위해 워드임베딩(word embedding)을 사용하여, 단어의 의미를 포함하는 벡터로 표현한다. 워드임베딩의 대표적인 방법에는 Word2Vec 방법이 있는데, 원핫벡터를 선형변환행렬을 통해 임베딩 벡터를 구하는 것이다. 주변 단어를 입력받아 중심 단어를 예측하는 CBoW(Continuous Bag of Words)나 중심 단어를 입력받아 주변 단어를 예측하는 Skip-gram과 같은 학습 모델이 사용된다. 이후 이렇게 구해진 값들을 딥러닝에서는 입력으로 받아 학습을 수행하는데, 이를 언어모델이라고 한다. 대표적으로 Seq2Seq(Sequence-to-Sequence) 모델은 입력된 단어의 시퀀스로부터 다른 시퀀스를 출력한다. 그밖에 Attention 모델, Transformer 모델, 이를 활용한 BERT(Bidirectional Encoder Representations from Transformers) 모델 등이 있다.
도움 받은 글
1. 방송통신대학교 컴퓨터과학과 강의록
2. K-Nearest Neighbor(KNN), https://velog.io/@jesuiszoe/K-Nearest-Neighbor-KNN
3. 머신러닝 - 차원 축소(PCA, LDA, SVD, NMF), https://blog.naver.com/PostView.naver?blogId=paragonyun&logNo=222465847517&from=search&redirect=Log&widgetTypeCall=true&directAccess=false
4. 나무위키, 서포트 벡터 머신, https://namu.wiki/w/%EC%84%9C%ED%8F%AC%ED%8A%B8%20%EB%B2%A1%ED%84%B0%20%EB%A8%B8%EC%8B%A0
5. 나무위키, 앙상블, https://namu.wiki/w/%EC%95%99%EC%83%81%EB%B8%94https://blog.naver.com/PostView.naver?blogId=paragonyun&logNo=222465847517&from=search&redirect=Log&widgetTypeCall=true&directAccess=false
'PM으로 성장하기 > 개발 공부' 카테고리의 다른 글
| MSA, Message Queue, Apache Kafka (0) | 2023.05.07 |
|---|---|
| 인 메모리 데이터베이스와 Redis (2) | 2023.05.03 |
| [컴과] 인공지능: 개요, 지식기반 시스템, 탐색문제풀이, 게임트리, 퍼지이론, 컴퓨터시각, 기계학습, 인공신경회로망, 심층학습 (1) | 2022.12.02 |
| [컴과] Linux(리눅스): 소개, CLI, 셸, 명령어, 디렉토리와 파일, 운영체제, 사용자관리, vi, 파일시스템, 프로세스 관리, 소프트웨어 관리, 네트워크 관리, 원격제어, 웹서버 (0) | 2022.11.28 |
| [컴과] Python(파이썬): 개요, 구성요소, 객체와 클래스 (0) | 2022.11.22 |




댓글