인공지능이란?

인공지능이란 인간의 학습능력과 추론능력, 지각능력을 구현하는 컴퓨터 과학의 분야 중 하나이다. 최초의 신경망 모델은 1943년에 제안되었으며, 1950년 튜링 테스트가 제안되고, 1956년 다트머스 대학교에서 인공지능이라는 용어를 처음 사용하였다. 이후 많은 관심과 연구결과가 이루어졌지만 정보처리의 능력과 정보량의 부족으로 연구자금지원이 중단되며, 1969년 마빈 민스키와 시모어 페퍼트가 "퍼셉트론"이라는 책을 출간하며 지적한 한계로 인해 1970년대 1차 겨울기를 맞는다. 이후 1974년 역전파 알고리즘, 전문가 시스템의 성장 등으로 많은 연구가 있었지만 성장은 지지부진하여 2차 겨울기를 맞는다. 1990년대 이후부터는 문제해결과 비즈니스 중심으로 좁은 분야에 활용되고, 하드웨어의 성장, 2006년 제프리 힌턴 교수에 의한 딥러닝 논문으로 계속적으로 결과물이 나타나고 있다. 인공지능의 분야로는 기계학습, 자연어처리, 컴퓨터 시각, 로봇/자동차, 음성처리, 예술 등 다양하다.
지식 기반 시스템
지식 기반 시스템(knowledge-based system)이란 복잡한 문제를 해결하기 위해 지식을 사용하고 추론하는 컴퓨터 프로그램이다. 지식기반 시스템은 문제를 풀 때 활용할 수 있는 지식이 모여있는 지식베이스와 지식베이스의 지식을 활용하는 추론기관이 있으며, 이를 작동할 수 있는 사용자 인터페이스가 있다. 지식베이스와 추론기관이 분리되어 있는 것이 특징이다.
사람이 알고있는 지식과 컴퓨터의 내부 지식 간의 매핑은 잘 이루어져 있어야 한다. 실세계의 의미를 최대한 수용할 수 있어야 하며, 새로운 지식을 쉽게 습득할 수 있어야 한다. 이러한 지식을 표현하는 데에는 여러 유형이 있다.
1. 논리
명제를 이용하여 지식을 표현하고, 논리 연산자를 이용하여 복합적인 명제를 표현할 수 있다. 예를 들어 '이것은 고양이다'를 CAT으로, '고양이면 귀엽다'를 CAT → CUTE로 표현할 수 있다. 또한 명제를 술어와 객체로 분리하여 표현하고, 변수를 사용할 수도 있다. '코숏은 고양이다'를 CAT(코숏) 으로 표현하고, 변수를 사용하여 CAT(x) 형태로도 표현할 수 있다.
2. 규칙
IF 가정 THEN 결론 표현을 사용하여 주어진 상황을 가정하고 결론을 내릴 수 있다. 또한 추론의 방법으로 연역법, 유도법, 귀납법을 사용할 수도 있으며 가정부와 결론부의 순서를 조정하여 전방향 추론과 후방향 추론을 할 수 있다.
3. 시맨틱 네트워크
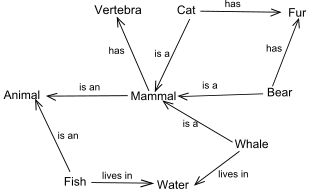
시맨틱 네트워크란 네트워크를 기초로 한 표현 방법으로, 개념 간의 관계를 표현할 수 있다. 시맨틱 네트워크는 1956년 자연어를 지식으로 표현하기 위해 리처드 리첸스가 창안한 방법이다.
시맨틱 네트워크는 노드와 아크로 이루어져 있다. 노드란 객체를 의미하고 아크는 노드 간의 관계를 표현한다. 아크는 상하위 클래스를 나타내는 ako(a kind of), 클래스의 사례를 나타내는 isa(is a), 객체의 부속품을 나타내는 has-part로 표현할 수 있다. 또한 '상속'이라는 개념을 도입할 수 잇는데, 상속이란 상위 클래스의 속성을 하위 클래스가 이어받는 것을 말한다.
4. 프레임
프레임은 마빈 민스키가 1974년에 제안한 개념으로 상위개념, 하위개념, 사례를 각각 클래스, 부클래스, 사례프레임의 형태로 표현한 것이다. 이다. 프레임은 대상의 속성(슬롯)의 집합이며, 각각의 슬롯에는 기본값을 설정하거나 프로시저를 추가할 수 있다. 프로시저에는 if-needed 프로시저(값이 있어야 하는 경우 계산하여 값을 제공), if-read 프로시저(다른 인터페이스를 읽으면 동작), if-written 프로시저(어떤 값이 기록되면 동작). if-removed 프로시저(어떤 슬롯이 제거되면 동작)이 있다.
4. 신경회로망
인간의 신경망을 본 따 뉴런과 뉴런을 연결하는 연결관계를 계층적으로 표현한 것이다. 아래 층은 기본 지식이 되고, 올라갈 수록 고차원 지식으로 표현된다.
전문가 시스템
지식 기반 시스템은 인공지능 연구원들에 의해 개발되었으며, 초기 지식 기반 시스템은 '전문가 시스템'이었다. 전문가 시스템이란, 주어진 문제를 인간 전문가의 문제해결과 전략에 따라 시뮬레이션하여 문제풀이와 의사결정을 지원해주는 시스템을 말한다. 현장 전문가는 문제를 풀기 위해 사용하는 규칙과 전략을 보유하고 있어야 하며, 공학자는 전문가의 지식을 지식 베이스로 만들어야 한다.
탐색 문제 풀이
탐색 알고리즘이란, 방대한 데이터에서 목적에 맞는 데이터를 찾기 위한 알고리즘을 말한다. 이러한 탐색의 문제를 푼다는 것은 초기 상태에서 시작하여, 목표 상태에 도달할 수 있는 일련의 연산자를 찾는 것이다. 이를 위해서 문제는 적절한 자료구조로 변환되어 연산이 용이해야 하며, 연산자는 어느 한 상태에서 다른 상태로 변화시킬 수 있어야 한다. 또한 연산자를 통해 얻을 수 있는 모든 상태의 집합인 '상태공간'이 있으며, 상태공간을 활용하기 위해 초기상태와 목표상태 및 연산자를 정의해야 한다. 즉, 트리 탐색에서는 1) 최초시작점, 2) 목표지점, 3) 현재 노드에서 다른 노드로의 이동, 4) 이동비용이 주를 이룬다.
탐색 과정
탐색은 다음과 같은 과정으로 실행된다. 먼저 노드를 선택하고, 노드에 적용할 수 있는 모든 연산자를 통해 후계노드를 생성하여 확장한다(후계노드에는 부모노드를 가리키는 포인터를 갖고 있다). 후계노드에는 목표노드가 있는지 검사하며, 없다면 다음 노드를 선택하여 탐색 과정을 반복한다. 탐색 시에는 앞으로 확장할 노드를 저장하는 리스트, 이미 확장한 노드를 저장하는 리스트가 있으며 탐색 과정에서 확장할 노드 리스트의 노드를 꺼내 확장한 노드 리스트로 옮긴다.
탐색의 종류
탐색 방법은 깊이 우선 탐색, 너비 우선 탐색, 균일비용 탐색, 언덕오르기 탐색, 모의 담금질, A*알고리즘 등이 있다. 깊이 우선 탐색, 너비 우선 탐색, 균일비용탐색은 목표노드의 위치와 상관없이 노드를 확장한다. 반면 언덕오르기 탐색, 모의담금질, A*알고리즘은 경험적 탐색(heuristic search)으로, 100% 맞지는 않지만 개연성이 있는 경험적 정보를 사용하여 탐색한다. 이 때 경험적 지식을 '평가함수'라는 것에 반영한다.
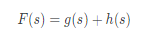
평가함수란 어떤 상태가 주어졌을 때, 그 상태를 거쳐가는 것이 목표로 가는 데에 얼마나 바람직한가를 나타내는 함수이다. 평가함수 F(s)는 출발노드로부터 지금의 노드까지 도달하는 데 소비한 경로비용 g(s)에, 앞으로 목표까지 도달하는 데 들어갈 비용의 예측치 h(s)를 더한 값이다. F(s)가 제일 작은 s를 우선적으로 탐색하는 전략으로 탐색이 수행된다.
1. 깊이 우선 탐색(DFS, depth-first search), 너비우선탐색(BFS, breadth-first search)
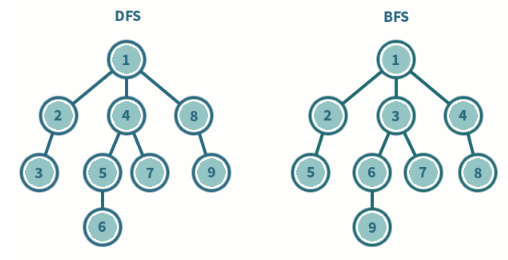
깊이 우선 탐색은 가장 최근에 생성한 노드를 먼저 확장하는 방식으로, 깊이를 우선으로 탐색하는 방법이다. 이 경우 목표에 도달할 수 없는 경로를 계속 탐색할 수도 있어, 깊이 제한을 정하여 탐색한다. 반면 너비 우선 탐색은 생성된 순서에 따라 노드를 확장하는 방식으로, 트리의 레벨 순서에 따라 노드를 탐색하는 방법이다.
2. 균일비용 탐색(uniform-cost search)
노드와 노드 사이를 이동하는 경로 비용을 고려하는 것으로, 출발한 노드로부터 경로비용이 최소인 노드를 선택하여 확장하는 방법이다. 평가함수의 h(s)는 고려하지 않는다.
3. 언덕오르기 탐색
현 상태를 확장하여 생성한 후계노드 중에서 다음에 확장할 노드를 선택하되, 후계노드별 평가함수를 계산하여 비용이 적은 노드를 선택하여 확장하는 방법이다. 이 때 평가함수는 평가함수의 g(s)는 고려하지 않는다.
5. 모의담금질(simulated annealing)
주어진 노드의 평가함수만으로 판별하는 것이 아닌, 전체적으로 보았을 때 평가함수가 최소인 해를 구하기 위한 접근 방법이다. 예를 들면 산의 정상으로 가기 위해 지금보다 더 높은 고도인 방향을 선택한다고 했을 때, 고원이나 골짜기를 만나면 전체 영역에서의 최고점(정상)에는 도달하지 못할 수 있다. 이 때 일정 확률로 다른 해가 있는지 시도해봄으로써, 최적의 해를 구하고자 하는 것을 말한다.
6. A* 알고리즘
확장할 노드를 저장한 리스트에서 노드를 꺼내 이미 확장한 노드를 저장하는 리스트에 넣는다. 해당 노드를 확장하여 후계노드를 생성하고, 해당 후계노드를 '확장할 노드를 저장한 리스트'에 다시 넣는다. 이때, 중복으로 생성된 노드가 있다면 평가함수가 큰 노드를 제거하고 부모노드의 포인터를 수정한다.
게임 트리
상대가 존재하는 경쟁형으로 구성된 문제에 속하는 탐색 알고리즘이 있다. 예컨대 만약 상대방과 바둑을 둔다면, 앞으로 진행될 몇 수에 대한 게임 트리로 최적의 수를 찾을 수 있다.
1. 최대 최소 탐색(minimax search)
나는 내게 가장 유리한 수(가장 가치가 높은 수)를 둘려고 할 것이고, 상대방은 내게 가장 불리한 수(가장 가치가 낮은 수)를 둘려고 할 것이다. 즉 현재 내가 둘 차례가 되었고 만약 내가 둘 수 있는 수가 A, B, C 세 가지가 있고 각각의 가치가 3, 4, 5 일 때 나는 C를 둘 것이다. 반대로 현재 상대방이 둘 차례가 되었고 상대방이 둘 수 있는 수가 D, E, F 세 가지고 있고 각각 가치가 6, 7, 8일 때 상대방은 D를 둘 것이다. 이러한 최대화, 최소화 과정을 시뮬레이션한 것이 최대 최소 탐색이다. 최대최소 탐색을 진행할 때에는 정해진 깊이나 시간을 두어 앞으로 둘 수를 판단한다. 이 때 가치함수를 통해 수들의 가치를 평가한다.
2. α-β 가지 치기
최대 최소 탐색에서 탐색이 불필요한 가지를 잘라내어, 탐색의 성능을 개선한 알고리즘이다. 앞서 본 최대 최소 탐색에서는 규모가 커질수록 가지 수가 많아 계산시간과 자원이 많이 소요된다. 따라서 탐색범위를 좁히기 위해, 해당 방향을 가지치기하는 것이다.
최대화 과정에서 지금까지 구한 가장 큰 가치를 α, 최소화 과정에서 지금까지 구한 가장 작은 가치를 β라 놓고 각각의 수마다 α와 β를 구한다. 최소화 노드에서 후계노드의 가치가 α보다 작다면 탐색을 하지 않도록 최소화 노드의 나머지 후계노드를 가지치기하고, 최대화 노드에서 후계노드의 가치가 β보다 크다면 탐색을 하지 않도록 최대화 노드의 나머지 후계노드를 가지치기한다.
3. 몬테카를로 트리 탐색(Monte Carlo Tree Search, MCTS)
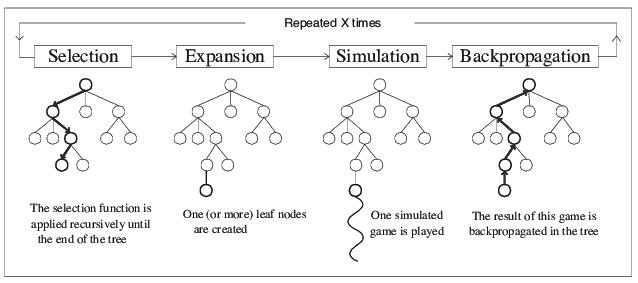
알파고에서도 사용된 몬테카를로 트리 탐색은 경험적 탐색 알고리즘으로, 탐색 공간의 무작위 표본을 바탕으로 탐색 트리를 구성한다. 이후 검토를 해본 경험을 바탕으로 '활용'하고, 한번도 시도해보지 않은 것을 '탐사'한다. 루트 노드로 시작하여 다음과 같은 절차를 거친다.
1) 선택과 확장: 루트노드로부터 시작하여 자식 노드를 선택하는 과정을 깊이 방향으로 확장한다.
- 자식 노드를 선택할 때에는 UCB 알고리즘 등을 이용하여 활용과 탐사의 균형을 맞출 수 있도록 설계한다
- 이후 선택된 노드에서는 새로운 행동을 통해 자식 노드를 생성하며 트리를 확장한다.
2) 시뮬레이션: 확장한 노드로부터 스스로 게임을 선택하여 게임에 따라 점수를 매긴다.
- 무작위 방법으로 스스로 수를 선택하여 게임을 진행할 수도 있다.
3) 역전파: 결과를 루트노드에 전달하여 업데이트 한다
- 결과치의 누적된 값과 방문 횟수를 노드에 저장하고, 평균을 사용하는 계산 방법이 있다
4) 최적의 자식노드 선택
- 최적의 노드를 선택할 때는 가장 큰 보상을 갖는 max child, 가장 많이 방문한 robust child, 큰 보상을 갖고 방문횟수가 가장 많은 max-robust child를 선택할 수 있다. 혹은 신뢰도 하한이 최대인 secure child를 선택할 수도 있다. 알파고는 robust child 를 선택했다고 한다.
※ 이미지 출처: Rocki, Kamil, and Reiji Suda. “Parallel monte carlo tree search scalability discussion.” Australasian Joint Conference on Artificial Intelligence. Springer, Berlin, Heidelberg, 2011
퍼지이론
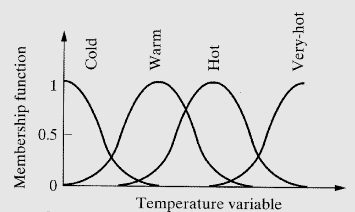
퍼지이론은 참, 거짓의 구분이 모호한 문제를 해결하기 위한 이론이다. 퍼지이론에서 퍼지집합은 어떤 대상이 해당 집합에 포함될 '가능성'으로 표현한다. 이러한 가능성을 표현하는 것은 소속함수(membership function)이다. 일반적으로 명제의 논리값은 참(1), 거짓(0)으로 표현되었는데 퍼지논리에서는 논리값이 0~1 사이의 값으로 표현된다. 퍼지집합은 일반적인 집합의 교환법칙, 결합법칙, 분배법칙 등을 만족한다.
퍼지추론은 IF 조건부 THEN 결론부의 형태로 규칙을 사용한다. 단순히 작다, 크다가 아닌 작다, 조금 작다, 보통이다, 조금 크다, 크다와 같은 라벨링이 가능하다. 이러한 퍼지 추론을 적용할 때는 입력한 사실과 퍼지 관계를 합성하여 구현한다.
예를 들어 에어컨에서 센서를 통해 현재 온도가 조금 높다라는 수준으로 전달되었다. 에어컨 내 추론부에서는 조금높다와 높다의 최소값을 구하고 최소값들의 최대값을 구하여 해당 수준에 맞게 에어컨 출력의 리미트를 걸 수 있다. 이와 같은 방식으로 조금높다와 낮다의 최소값들의 최대값을 구하여 에어컨 비출력의 리미트를 건다. 이렇게 도출된 에어컨 출력/비출력 그래프를 종합(논리곱)하여 해당 그래프들의 최대값을 구한다. 최종적으로 구한 그래프는 비퍼지화 과정을 거치는데, 예를 들면 무게중심 값을 활용할 수 있다. 이렇게 비퍼지화까지 완료되면 에어컨 출력 정도를 조정하는 특정 값을 도출하게 된다.
컴퓨터 시각
컴퓨터 시각(Computer Vision)은 인간의 시각체계를 컴퓨터에 심어넣기 위한 인공지능의 한 분야이다. 컴퓨터 시각은 생체인식, 영상 분석, 제품 결함 검사, 보안시스템, 로봇, 자율주행 등 다양한 분야에서 사용된다. 컴퓨터시각의 처리 단계는 아래와 같은 순서를 거친다.
1. 영상 취득: 센서를 통한 영상 취득
영상 센서, 적외선 센서, 레인지 센서 등을 통해 영상을 취득할 수 있다. 디지털 영상의 색 정보는 RGB, 그레이 레벨 히스토그램 등으로 표현된다. 또한 주로 사각형 픽셀 구조를 가지며, 각 픽셀은 연결성에 따라 이웃이라는 개념을 정의하여 픽셀의 연결을 확인할 수 있다.
디지털영상은 아날로그 영상을 디지털화한 것이다. 이렇게 디지털화를 하기 위해서는 표본화와 양자화 과정을 거친다. 표본화란 아날로그 신호를 이산 신호로 변환하는 것으로, 해상도를 결정하게 된다. 양자화는 표본화된 화소의 밝기와 색을 몇 단계의 값으로 근사화하는 것으로, 각 구간의 대표값을 부여하는 과정이다.
2. 전처리: 취득한 영상을 가공(훼손 및 잡음 제거, 개선, 변환)
전처리 단계에서는 필터를 사용한다. 필터는 불필요한 요소를 제거하고 시스템에 필요한 요소만을 남기는 것이다. 저역 통과 필터는 주파수가 높은 부분을 억제하여 부드러운 영상을 추출하며, 고역 통과 필터는 주파수가 높은 부분만 남겨 변화가 급격한 부분만 얻어낼 수 있다. 이러한 필터를 공간 영역에서 적용한다면 필터 마스크를 합성곱 연산을 수행한다. 합성곱 영상 필터링 시에는 주변 값과 적절하게 혼합하여 결과 값을 계산한다. 이 때 필터를 과도하게 사용하여 잡음을 지나치게 제거할 경우, 경계가 사라지는 blurring 현상이 발생할 수 있다.
대표적인 잡음 중 하나는 가우시안 잡음으로, 평균을 기준으로 가우시안 분포를 갖는 잡음이다.

가우시안 저역 통과 필터는 가중치를 모두 더하면 1이 되는 것으로, 평균 필터를 적용한 것보다 blurring 현상이 덜하다. 한편 점 잡음이라는 것도 있는데, 점 잡음은 흰 점과 검은 점이 무작위로 나타나는 잡음을 말한다. 이 때는 중간값 필터를 사용하는데, 각 필터의 정해진 크기 내 픽셀 값 중 중간 값을 선택하여 적용하는 것을 말한다.
3. 영상 분할: 유사한 성격의 영상은 묶고, 상이한 특성의 부분은 다른 영역으로 구분
영상 밝기, 색, 성분, 텍스처 등을 고려하여 영상을 구성하는 물체를 구분하여 분할한다. 각 영역은 정해진 기준에 따라 속성이 규닝해야 하고, 인접한 영역은 다른 속성을 가지며, 경계는 정확한 위치에 존재해야 한다. 영상을 분할하는 방법은 다음과 같은 세 가지 방법이 있다.
첫째, 임계치에 의한 이진화이다. 영상 밝기에 따라 임계치를 기준으로 0과 1을 골라 이진 영상을 만든다. 임계치를 결정하는 방법에도 여러 가지가 있는데, 픽셀 수 비율에 따라 결정할 수 있다. 그레이 레벨 히스토그램의 정점이 2개 인 경우 그 사이에 존재하는 최소값을 임계치로 설정할 수 있다. 혹은 영상 영역을 클래스로 나누고 클래스 간 분산을 총 분산으로 나눈 값이 최대가 되는 값을 임계치로 정할 수도 있다.
둘째, 영역의 공간적 특성을 이용하는 방법이 있다. 어떤 영역이 인접 영역과 유사한 속성을 갖는다면 하나의 영역으로 결합하고, 내부가 균일하지 않다면 분할한다. 4분 트리 분할 알고리즘은 영역을 4개로 나누어 위 과정을 반복하는 것이다.
셋째, 경계를 검출하는 것이다. 그레이 레벨이 크게 변하는 부분을 엣지(edge)라고 하는데, 이를 찾는 것이다. 소벨 연산자는 한 번 미분을 하는 방법으로 엣지를 구하는 것이다. 수직, 수평 방향의 필터 마스크를 정의하여 엣지의 강도와 방향을 정한다. 라플라스 연산자는 앞서 미분한 것을 한번 더 미분하는 방법이다.
4. 정규화: 크기, 위치, 방향, 밝기, 대비 등을 기준이 되는 형태로 맞추기
5. 영상 표현: 분할된 영역들의 영역의 특징을 추출
특징이란 패턴 식별에 사용되는 정보를 말한다. 특징은 수치 형태인 벡터로 표현할 수 있다. 특징을 구성하는 각 요소들을 하나의 축으로서 구현한 특징 공간으로 표현할 수 있다. 즉 n개의 특징이 있다면, 이를 n차원 특징공간으로 나타낼 수 있는 것이다. 예를 들어 HoG(Histogram of Oriented Gradients)는 영상의 기울기를 사용하여, 각도를 9개로 나누어 히스토그램 형태로 표현한 것이다. 이는 자율주행차량의 보행자 식별 시 사용되기도 한다.
이러한 벡터는 상관관계를 최소화하여 컴팩트하게 표현할 수 있다. 상관관계가 높다는 것은 대표값을 하나만으로 둘 수 있다는 것으로서, 이러한 상관관계를 최소화한다면 계산량을 줄일 수 있다. 이 때 주성분 분석(principal component analysis, PCA)을 사용한다. 주성분 분석은 고차원의 데이터를 저차원의 데이터로 환원하는 기법으로, 새로운 좌표계로 데이터를 선형 변환하는 것이다.
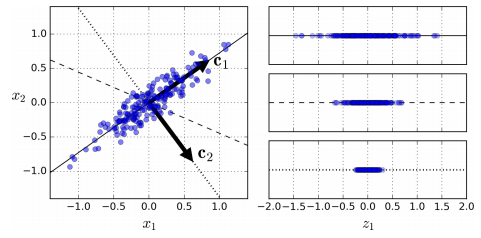
이렇게 벡터값이 정해졌다면 어떠한 패턴이 다른 패턴과 비슷한지, 다른지를 구분하기 위해서 거리를 측정하게 된다. 이 때 사용하는 것이 거리측정자(distance measure)이라는 것인데, 거리를 측정하는 데에도 여러가지 도구들이 있다. 직선거리를 구하는 유클리드 거리, bool값을 계산하는 해밍거리, 각각의 축의 합을 구하는 도시블록 거리, 축의 성격이 다른 경우 사용할 수 있는 마할라노비스 거리가 있다.
6. 분석: 분할된 영역들의 특징을 바탕으로 필요한 정보를 얻음
특징을 추출하고 패턴을 인식하였다면 이제는 특정 클래스로 분류를 해야 한다. 이 때 통계적 분류 기법을 사용할 수 있다. 미지의 점 x가 클래스A에 속할 확률 p(ClassA|x)과 클래스B에 속할 확률 p(ClassB|x)을 비교하여 더 큰 클래스로 분류한다. 베이즈정리를 사용한다면 각 클래스에 속할 확률을 구할 수 있다.
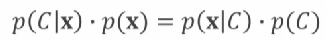
학습 표본을 통해서 p(x|C)와 p(C), p(x)는 알고 있기 때문에 위 공식을 이용한다면 p(C|x) 값을 구할 수 있다. 다만 확률분포를 알아야 하는데, 확률분포를 결정하는 방식에는 매개변수 방식과 비매개변수 방식이 있다. 매개변수 방식은 특징공간 상 패턴의 분포가 잘 알려진 모델을 따른다고 가정하는 것이다. 예컨대 가우시안 모델을 따른다고 가정한다면 표준편차와 평균을 구하여 분포의 모양을 정할 수 있다. 학습 표본 집합을 통해 평균과 분산 등의 매개변수를 추정한다. 매개변수 방식에서 확률을 추정하는 방법 중 하나는 최대가능도 추정(maximum likelihood estimation)이 있다. 학습 표본 집합이 관찰될 가능성이 최대인 매개변수를 찾는 방법이다. 이 때 '가능도'라는 것을 이용하는데, 가능도는 특정 매개변수 값을 가정했을 때 표본집합이 나타날 표본 각각의 확률을 모두 곱하여 계산한다. 가능도가 최대값인 매개변수가 최적의 값이 된다. 다시 돌아가 미지의 점 x는 각 클래스마다 결정된 매개변수값을 이용하여 확률값을 구했을 때 어떤 클래스의 값이 큰지에 따라 클래스를 분류할 수 있다.
반면 비매개변수 방식은 근접한 위치에 있는 패턴이 같은 클래스에 속할 가능성이 높다고 가정하는 것이다. 따라서 거리측정자와 학습 표본 집합을 이용하여 미지의 점 x와 클래스의 거리를 측정한다. 비매개변수 방식의 대표적인 방법은 k-근접이웃(k-NN, k-Nearest Neighbor)이 있다. k-근접이웃은 학습 표본 데이터들 중에 미지의 점 x에 가장 가까운 k개의 표본 중 클래스A에 속하는 표본이 k'개라면 k'/k로 x가 클래스A에 속할 확률을 구하는 것이다. 미지의 점 x는 k'/k가 가장 큰 클래스에 속한다고 할 수 있다.
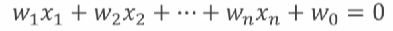
위와 같이 확률을 이용하지 않고 특정한 판별식을 이용하는 방법도 있다. 선형판별식의 경우 아래와 같은 방정식 형태로 구성한다. 값이 0이 되는 것은 경계에 해당하는 것이며, 해당 값보다 크거나 작거나에 따라 클래스를 식별한다. 이러한 판별식을 만들기 위한 가중치w는 기계학습을 통해 학습된다.
기계학습(Machine learning)
인공지능 시스템은 지능적인 행동 능력을 갖기 위해 외부 정보를 이용하여 내부에 지식을 형성하고 저장한다. 이 과정을 기계학습이라고 한다. 기계학습의 종류는 아래와 같다.
- 지도학습(supervised learning): 입력과 기대 출력을 학습 데이터로 전달하여 입력=기대출력이 되도록 학습
- 비지도학습(unsupervised learning): 입력만 제공하여 유사한 입력에는 동일한 출력을 내도록 학습
- 강화학습(reinforcement learning) : 현재 상태에서 어떤 행동을 하는 것이 최적인지를 학습하기 위해 행동할 때 마다 보상을 주어, 보상을 최대화하는 방향으로 학습
- 준지도학습: 라벨이 지정되지 않은 큰 규모의 학습 표본 집합과 비교적 작은 규모의 라벨이 지정된 학습표본 집합을 사용하여 학습
대표적인 학습 방법은 아래와 같다.
결정 트리
학습 방법의 사례로는 결정트리가 있다. 분할 정복 방식의 결정트리는 특징 공간을 분할하고 입력 대상을 분류하거나 회귀분석하는 트리를 말한다. 루트 및 내부노드는 공간을 분할하는 조건을 판단하는 함수를 갖고 있으며, 트리의 말단인 잎 노드는 출력값을 갖고 있다. 결정트리 학습은 학습 표본을 바탕으로 지도학습 방식으로 학습하여, 각 노드별로 불순도 검사를 시행한다. 불순도 검사에는 엔트로피(Entropy), 지니지수(Gini index) 등을 사용한다. 분할할 영역을 가정하고 각 영역에 대해 불순도를 구한다음, 그 중 불순도가 낮은 방법을 채택하여 나눈다. 불순도를 낮추어 더이상 분할할 수 없는 클래스를 출력하는 잎 노드를 생성하는 것이다.
선형 회귀와 경사하강법
회귀분석이란 입력(독립변수)과 출력(종속변수)의 상관관계를 추정하는 기법이다. 선형회귀는 이 둘의 상관관계를 선형함수로 모델링한 것이다.
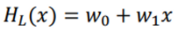
선형회귀는 학습 표본 집합으로부터 선형가설을 구하는 것이 그 목적이다. 선형가설과 실제 데이터에서는 오차가 발생할 수 밖에 없으므로 이 오차를 줄이는 방향으로 학습을 하여 w값을 구한다. 오차는 비용함수로 정의가 되는데, 평균제곱오차(mean squared error, MSE) 등 여러 방법으로 정의할 수 있다. 이러한 비용함수를 줄이기 위해 경사하강법(Gradient Descent)을 사용할 수 있다. 비용함수가 오목/볼록한 함수라는 것을 전제하여, 반드시 최소점이 존재한다고 가정한다. 기울기의 음의 방향으로 경사면을 따라 내려가는데, 학습률을 통해 미세하게 w값을 변화시킨다.
로지스틱 회귀
로지스틱 회귀는 종속변수가 0 또는 1이라는 값을 낼 수 있다는 가설을 구하는 것으로, 분류 문제에서 사용된다. 로지스틱 회귀에서는 로지스틱 함수를 사용한다.
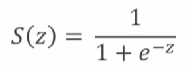
로지스틱 회귀에서의 가설은 선형함수를 로지스틱 함수에 넣어 0과 1사이의 값을 갖는 가설을 구하는 것이다. 마찬가지로 비용함수를 정해야 하는데, 로지스틱 회귀의 비용함수는 w에 따라 특정한 학습 표본이 발생할 확률로 구하며, 이를 활용한 것이 교차 엔트로피(cross entropy)이다. 마찬가지로 경사하강법에 의해 학습을 시킬 수 있다.
다항 로지스틱 회귀는 클래스가 3개 이상인 것으로, 로지스틱 함수가 아닌 softmax 함수를 사용한다. softmax 함수는 n개의 입력이 들어오면 입력은 0과 1사이의 값이 되고 총 합이 1이 되는 확률밀도와 비슷한 것이다. 즉, 각각의 클래스에 속할 확률을 계산하는 것과 유사하다.
군집화
군집화는 패턴 집합이 주어졌을 때 같은 종류라고 여길 수 있는 클래스로 분할한 것이다. 군집화 알고리즘에는 k-평균 군집화(k-means clustering)가 있다. 우선 초기 위치를 임의로 혹은 학습 표본 중에 랜덤하게 선택한다. 이후 초기 위치를 기준으로 군집을 나누고, 구획의 평균 벡터를 구한다. 새로 구한 평균 벡터는 이제 새로운 평균 벡터가 되고, 다시 이를 기준으로 군집을 나눈다. 나뉜 구획에 속한 벡터들의 평균 벡터를 구하면서 벡터 값을 업데이트한다.
인공신경회로망(Artificial Neural Network, ANN)
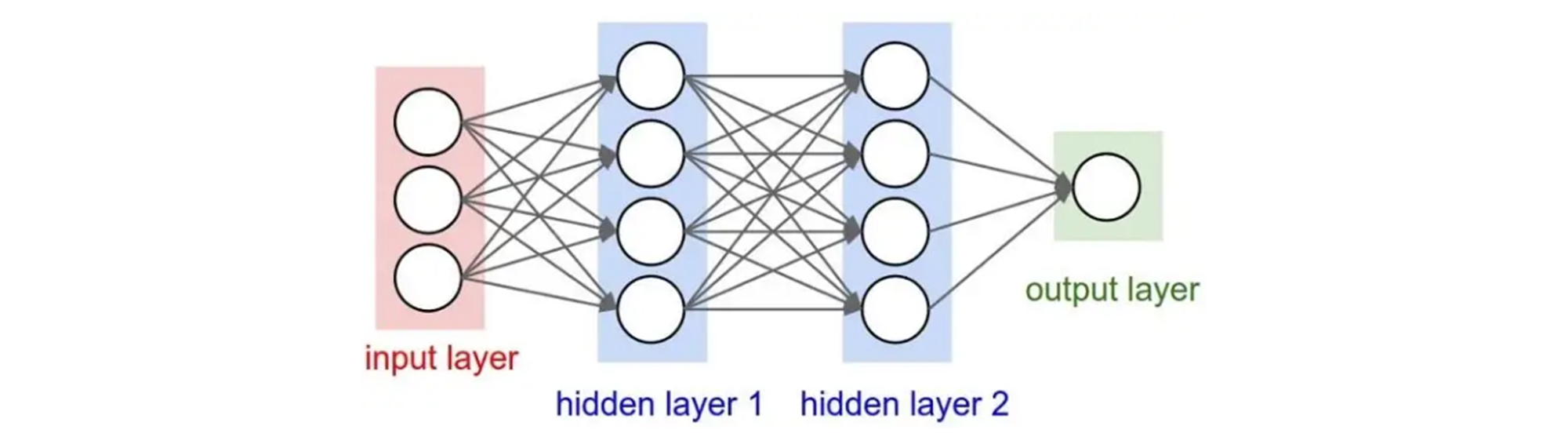
인공신경회로망이란 기계학습과 인지과학에서 신경망에서 영감을 얻은 통계학적 학습 알고리즘이다. 인공신경망은 시냅스의 결합으로 네트워크를 형성한 인공 뉴런(노드)이 학습을 통해 시냅스의 세기를 변화시켜 문제 해결 능력을 가지는 모델을 가리킨다. 입력은 가중치 w에 따라 합산되는 활성함수 f에 따라 출력값을 만들어낸다. 활성함수의 종류는 다음과 같다.

- Hard limit : 함수의 입력이 0보다 크면 1, 그렇지 않으면 0을 출력
- Sigmoid : S자 형태의 곡선으로 작은 입력에 대해서 이득이 크고, 큰 입력에 대해서는 이득이 작음
- TanH : -1과 1 사이의 값을 가짐
- ReLU : 입력이 0보다 작으면 0, 그렇지 않으면 x에 비례하여 출력
신경회로망의 학습
신경회로망에서 학습이 되어야하는 대상은 연결가중치 w이다. 학습 표본을 어떻게 시스템에 적용하느냐에 따라 세 가지 방법으로 학습을 분류한다. 배치 학습은 전체 학습 표본에 대한 누적 w의 변화분을 반영한다. 온라인 학습은 개별 학습 표본에 w의 변화량을 계산하여 반영한다. 미니배치 SGD는 학습 표본 집합의 일부를 미니 배치로 구성하여 미니 배치 단위로 w의 변화분을 반영한다.
퍼셉트론
퍼셉트론은 Hard limit 활성함수와 지도학습 방식을 적용한 모델로, 선형분리가 가능한 입력벡터의 집합에 대한 선형분리 경계면을 학습할 수 있다는 것을 입증한 모델이다. 학습 데이터를 통해 나온 결과값과 기대결과의 차이를 줄이는 방향으로 학습을 진행한다. 하지만 선형분리가 되지 않는 문제는 해결이 불가능하다는 한계가 있는데, 대표적으로 XOR 문제가 있다. 아래 이미지와 같이 검은 원과 흰 원은 어떠한 선으로도 구분할 수 없다.
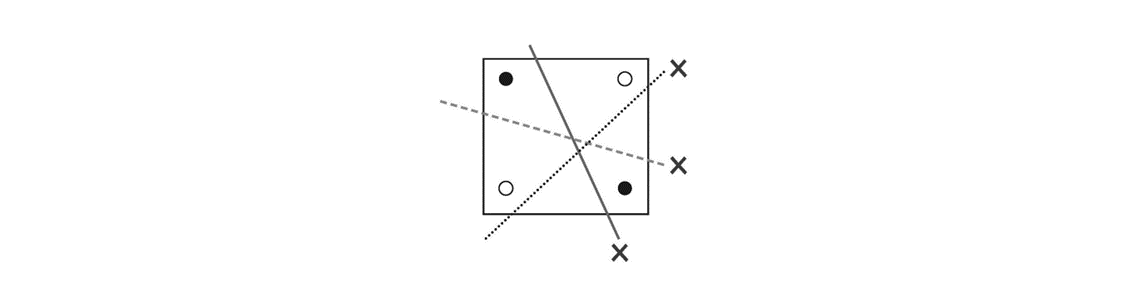
XOR 문제를 해결하기 위해서는 2개의 퍼셉트론을 구성하여 새로운 공간(은닉층)을 형성하고, 새로운 공간에 매칭하여 선형 분리를 시킬 수 있다. 하지만 이렇게 형성된 새로운 공간에 대해 어떻게 학습을 시킬 것인가에 대한 문제가 남아있다.
오차역전파(Backpropagation, BP) 모델
오차역전파는 Sigmoid 활성함수를 적용하고 지도학습을 사용한 모델로, 은닉층을 포함한 다층 퍼셉트론을 학습시키는 모델이다. 우선 출력층-은닉층 간의 연결 가중치 조절은 출력층과 출력기대값의 오차를 줄이기 위한 방식으로 학습한다. 기대값의 차이를 제곱한 평균제곱오차 비용함수를 정의하고 이를 최소화하기 위해 경사하강법을 이용한다.
은닉층-은닉층 간의 연결 가중치 조정은 이전 단계의 출력값과 다음 단계가 학습한 연결가중치를 활용하여 연결 가중치를 조정한다. 이런 과정을 아래층까지 내려가서 입력층까지 내려간다. 경사하강법을 적용하는 과정에서 최적의 해에 접근할 수 있도록 관성항(또는 모멘텀)을 사용한다. 이는 이전 단계의 연결가중치 변화분을 관성계수를 사용하여, 이전 단계에서의 변화분을 일부 반영한다.
자기조직화 지도 모델(self-organizign map, SOM)

입력 값이 전달되면 2차원 뉴런 배열에 연결되고, 가장 매칭이 잘 되는 뉴런을 승자 뉴런으로 만들어 해당 출력은 강화하고 주변 뉴런은 억제하는 학습 방법이다. 승자뉴런과 함께 이웃뉴런도 변화하기 때문에 전체 학습 표본을 표현할 수 있는 맵이 만들어진다. 자기조직화 지도는 경쟁 학습 모델을 사용한다. 입력만 제공되고 기대되는 출력은 제시되지 않으며, 다른 노드들과의 경쟁을 통해 얻어내는 학습 모델이다.
학습 벡터가 주어지면 그에 잘 반응하는 승자 노드와, 승자노드 주변의 이웃들의 집합들은 학습벡터와 가까워지도록 이동한다. 더이상 이동이 되지 않도록 여러 번 반복하여 학습시키게 되고, 노드의 개수만큼 군집이 생기며 대표 벡터들이 형성된다. 이러한 대표 벡터들은 특징 벡터가 된다.
LVQ(Learning Vector Quantization)
LVQ는 자기조직화 지도 모델을 사용하여 분류 문제를 다루는 모델이다. 오차를 최소화하는 대표벡터의 위치를 구하는 것이 목적이다. LVQ는 지도학습 방식에 따라 대표벡터를 학습한다. 각 클래스 간에는 경계(결정경계)가 있으며, 학습 표본이 어떤 클래스에 가까운지 판별한다. 학습표본과 대표벡터의 클래스가 같다면 해당 클래스의 대표벡터가 학습표본에 가까워질 수 있도록 학습률에 따라 연결가중치를 강화하게 되고, 그러면서 클래스 간의 경계도 변한다. 반대로 학습표본과 대표벡터의 클래스가 다르다면 대표벡터가 학습표본에서 멀어지도록 학습률에 따라 연결가중치를 약화시키고, 이에 따라 클래스 간의 경계도 변화된다.
심층학습(deep learning)
심층학습은 심층 신경망을 학습시키는 모델이다. 심층 신경망은 입력층과 출력층 사이의 수많은 은닉층이 연결된 것이다. 문제가 복잡해질 수록 많은 층의 은닉층을 포함할 수 밖에 없다. 많은 은닉층을 학습시키는 것은 어려운 문제이다. 출력층에서 입력층 방향으로 오차 역전파를 수행할 때 미분을 하게 되는데, 층이 깊어질수록 오차는 작아지고 아래층으로 갈 수록 오차가 거의 전달되지 않아 학습이 이루어지지 못한다(경사소멸문제). 또한 특정 학습 데이터에 지나치게 의존하는 과적합 문제가 발생할 수 있다. 이러한 문제를 해결하고, 심층 신경망을 학습하기 위한 방법이 심층학습(딥러닝)인 것이다. 경사소멸문제를 해결하기 위해 연결 가중치 초기화, 활성함수 개선 등의 방법을 사용하고, 과적합문제를 해결하기 위해 드롭아웃 등을 사용한다.
학습 성능 개선
1. 드롭아웃
드롭아웃은 신경망을 학습하는 동안 적절한 확률에 따라 뉴런을 일시적으로 제거되어 선택적으로 학습하는 것이다. 최종적으로는 모든 뉴런을 사용하여 학습을 하게 되는데, 이 때 출력이 크게 나올 수 있으므로 드롭아웃된 비율을 고려하여 재조정한다.
2. 연결 가중치 초기화: 심층신뢰망(Deep belief nets, DBN)
초기 값을 랜덤으로 정하지 말고, 적절한 값으로 정한다면 성능을 개선할 수 있다. 심층 신뢰망을 사전 학습하여 연결가중치를 초기화하고, 몇 층을 추가하여 오차역전파를 통해 조정함으로써 성능을 개선하는 것이다. 심층신뢰망은 자율학습 신경망으로, 주어진 학습 표본 집합에 대해 자율학습을 하며 통계적으로 입력을 재구성한다.
볼츠만 머신(Boltzmann machine)이란 모든 노드들이 연결된 방식으로, 외부환경으로부터 정보를 입력받는 가시유닛과 입력한 것을 내부적인 표현을 만드는 은닉유닛으로 구성된다. 제한 볼츠만 머신(Restricted Boltzmann machine, RBM)은 가시유닛과 은닉유닛 간의 연결만 있는 방식이다. 제한 볼츠만 머신에서는 가시 유닛이 입력되었을 때 은닉 유닛이 1이 될 조건확률과 은닉 유닛이 주어졌을 때 가시 유닛이 1이 될 조건확률을 이용한다. 이러한 조건 확률을 깁스 샘플링(Gibbs sampling)을 이용하여 결합하고, Contrastive Divergence를 통해 은닉층의 출력을 다음 층의 가시층의 입력이 되어 층층이 유닛들의 값을 차례로 알아낸다. 심층신뢰망은 이와 같은 제한 볼츠만 머신을 활용하여 학습하고 그 결과에 한 층 이상을 추가하여 오차전역파를 통해 분류기가 된다.
3. 연결 가중치 초기화: fan-in & fan-out
연결가중치를 뉴런의 연결되는 입력 수(fan-in)과 출력이 몇 개의 뉴런에 연결되는(fan-out)에 따라 결정되는 값의 범위로 랜덤하게 초기화한다. 해당 범위를 균등분포, 정규분포 등으로 선택한다. 혹은 fan-in만을 고려하기도 한다.
4. 활성함수 개선
Sigmoid 활성함수는 아래층으로 내려갈 수록 오차가 덜 전파되기 때문에, Sigmoid 활성함수 대신 ReLU 함수를 사용한다. ReLU도 변형하여 Leaky ReLU, GELU 등을 사용할 수 있다.
5. 배치 정규화
미니 배치 단위로 학습 시 배치 단위 마다 데이터 분포를 일정하게 하여 학습 효과를 높이는 방법이다. 분포의 평균을 원점으로 맞추고, 표준편차를 조정하여 입력 분포를 정규화한다.
신경망 모델
1. 합성곱 신경망(Convolutional Neural Nets, CNN)
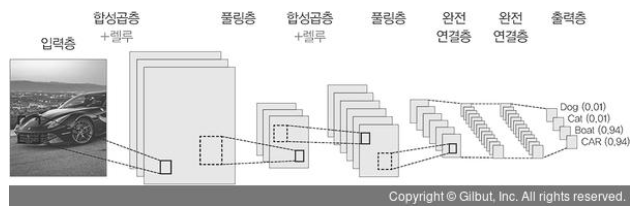
합성곱 신경망은 동물의 시각 피질을 모델링한 인공신경망으로, 시각적 영상을 분석하는 데 사용된다. 고양이는 시야의 한 쪽에 자극을 받으면 특정 뉴런만 활성화되고, 뉴런은 일정 범위 안의 자극에서만 활성화되는 근접 수용 영역을 가지며, 이러한 근접 수용 영역이 겹쳐져 전체 시야를 이룬다. 이에 영향을 받아, 얀 르쿤(Yann Lecan) 교수는 노드가 모두 연결되어 있는 기존 인공신경망이 아닌, 특정한 국소 영역에 속하는 노드들의 연결을 모델링하였는데 이것이 합성곱 신경망이다.
합성곱 신경망은 합성곱층(convolution layer), 통합층(pooling layer), 완전연결층(fully connected layer)으로 이루어져있다. 합성곱은 필터 적용에 활용되는 연산이며, 이동간격(stride)와 패딩값을 파라미터로 갖는다. 통합층은 입력을 서브샘플링하여 축소된 규모의 출력을 만드는 단계로, 필터의 크기를 정하여 통합하는 형태로 이루어진다. 보통 통합은 최대값을 선택하는 최대통합(max pooling)이 많이 사용된다. 이러한 합성곱층과 통합층 사이에는 ReLU 활성함수를 적용하는 층이 존재할 수도 있다. 완전 연결층에서는 반복된 합성곱층과 최대통합층이 연결되어 추론을 한다. 이러한 완전연결층은 분류기의 역할을 담당하게 되고, 출력층에서 softmax 함수를 통해 최종 결과가 출력된다.
2. ResNet(Residual Net)

층을 더 쌓을 수록 특징의 수준을 풍부해지지만, 학습 품질이 저하되는 문제가 발생할 수 있다. 이를 해결하기 위해서 Kaiming He는 층을 하나의 블록 F(x)로 묶고 해당 블록을 건너뛴 값 x과 블록값 F(x)을 더한 값 H(x)로 계산한다(스킵연결). 즉 H(x)는 F(x)와 x를 더한 값이 되며, F(x)는 H(x)에서 x를 뺀 잔여값이 되고, 이 잔여블록을 학습하는 것이다.
후기

AI는 우리 실생활에 가까워졌고 마케팅 도구로도 사용되고 있지만, 실제로 어떤 원리인지는 잘 알지 못했다. 내가 해봤던 것이라곤 챗봇을 운영하면서 인풋값을 만들어내고 거기에 라벨링을 붙이는 작업이었는데, 너무 많은 수작업이 들어간다고 생각했었다. 하지만 실제로 공부를 해보니 이러한 지도학습 외에도 비지도학습만으로 학습이 가능한 부분이 있어서 신기했다.
하지만 역시나 매우 어려운 과목이다. 일단 수학 및 통계지식이 많이 필요하다. 그래도 교수님이 굉장히 친절하게 설명해주시기도 하고, 여러 번 반복해서 읽고, 검색해보고, 이렇게 글로 정리해보니 점점 이해가 되는 것 같다. 물론 지금 배운 내용은 인공지능의 작은 부분 중 하나겠지만, 앞으로 배울 것의 기초를 쌓을 수 있는 좋은 시간이었다!
도움 받은 글
1. 방송통신대학교 컴퓨터과학과 강의록 일부
2. 나무위키, 인공지능, https://namu.wiki/w/%EC%9D%B8%EA%B3%B5%EC%A7%80%EB%8A%A5
3. 위키백과, 지능형 에이전트, https://ko.wikipedia.org/wiki/%EC%A7%80%EB%8A%A5%ED%98%95_%EC%97%90%EC%9D%B4%EC%A0%84%ED%8A%B8
4. 나무위키, 너비우선탐색, https://namu.wiki/w/%EB%84%88%EB%B9%84%20%EC%9A%B0%EC%84%A0%20%ED%83%90%EC%83%89
5. 나무위키, 탐색 알고리즘, https://namu.wiki/w/%ED%83%90%EC%83%89%20%EC%95%8C%EA%B3%A0%EB%A6%AC%EC%A6%98
6. 위키백과, 지식 기반 시스템, https://ko.wikipedia.org/wiki/%EC%A7%80%EC%8B%9D_%EA%B8%B0%EB%B0%98_%EC%8B%9C%EC%8A%A4%ED%85%9C
7. 위키백과, 시맨틱 네트워크, https://ko.wikipedia.org/wiki/%EC%8B%9C%EB%A7%A8%ED%8B%B1_%EB%84%A4%ED%8A%B8%EC%9B%8C%ED%81%AC
8. [AI 이야기] 인공지능의 결정적 인물들 (6)인간은 생각하는 기계, 마빈 민스키, https://www.letr.ai/blog/story-20211203
9. Forbes, Artificial Intelligence Defined As A New Research Discipline: This Week In Tech History, https://www.forbes.com/sites/gilpress/2016/08/28/artificial-intelligence-defined-as-a-new-research-discipline-this-week-in-tech-history/?sh=dd441d46dd15)
10. 신경망이란?, https://www.ibm.com/kr-ko/cloud/learn/neural-networks
11. 퍼지이론 Fuzzy Theory, https://happy8earth.tistory.com/501
12. [영상처리] 2차원 디지털 영상의 생성 (표본화, 양자화, 부호화), https://1coding.tistory.com/139
13. [파이선 OpenCV] 영상 잡음 제거 (1) - 미디언 필터 - cv2.medianBlur, https://deep-learning-study.tistory.com/163
14. 주성분 분석(PCA)이란?, https://butter-shower.tistory.com/210
15. 위키백과, 주성분 분석, https://ko.wikipedia.org/wiki/%EC%A3%BC%EC%84%B1%EB%B6%84_%EB%B6%84%EC%84%9D
16. 나무위키, 기계학습, https://namu.wiki/w/%EA%B8%B0%EA%B3%84%ED%95%99%EC%8A%B5
17. [인공지능]다층 퍼셉트론으로 XOR문제 해결하기, https://ang-love-chang.tistory.com/26
18. [ADsP] 정형 데이터 마이닝 - 군집분석(Clustering), https://velog.io/@zinu/ADsP-%EC%A0%95%ED%98%95-%EB%8D%B0%EC%9D%B4%ED%84%B0-%EB%A7%88%EC%9D%B4%EB%8B%9D-%EA%B5%B0%EC%A7%91%EB%B6%84%EC%84%9DClustering
19. 합성곱 신경망(CNN)/고양이의 눈에서 답을 얻다., https://ardino.tistory.com/38
20. 딥러닝 텐서플로 교과서, 5.1.2 합성곱 신경망 구조, https://thebook.io/080263/ch05/01/02/
21. [딥러닝] ResNEt의 개념, https://losskatsu.github.io/machine-learning/resnet/#
'PM으로 성장하기 > 개발 공부' 카테고리의 다른 글
| 인 메모리 데이터베이스와 Redis (0) | 2023.05.03 |
|---|---|
| [컴과] 머신러닝: 소개, 분야, 분류, 회귀, 군집화, 특징추출, 앙상블학습,결정트리, 서포트 벡터 머신, 랜덤포레스트, 인공신경망, 딥러닝 (1) | 2022.12.06 |
| [컴과] Linux(리눅스): 소개, CLI, 셸, 명령어, 디렉토리와 파일, 운영체제, 사용자관리, vi, 파일시스템, 프로세스 관리, 소프트웨어 관리, 네트워크 관리, 원격제어, 웹서버 (0) | 2022.11.28 |
| [컴과] Python(파이썬): 개요, 구성요소, 객체와 클래스 (0) | 2022.11.22 |
| [컴과] C++ 언어: 개요, 구성요소, 상속, 템플릿, 예외처리 (0) | 2022.11.20 |




댓글